Self-Reflective RAG with LangGraph
使用 LangGraph 实现自反思 RAG 系统
原文: Self-Reflective RAG with LangGraph作者: Ankush Gola 发布日期: 2024年2月7日
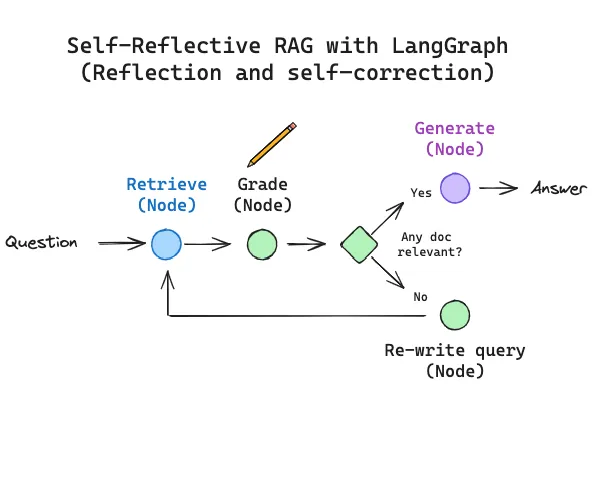
概述
本章介绍如何使用 LangGraph 实现自反思 RAG (Self-Reflective RAG) 系统。我们将探索两种前沿方法:CRAG (Corrective RAG) 和 Self-RAG,并学习如何通过 LangGraph 将这些研究论文的概念转化为实际可用的代码。
相关资源
一、动机 (Motivation)
大多数大语言模型 (LLM) 只是定期在公开数据语料库上进行训练,因此:
- 缺乏最新信息 - 训练数据有截止日期
- 无法访问私有数据 - 企业内部文档、个人笔记等
检索增强生成 (RAG) 是解决这些限制的核心范式,它通过将 LLM 连接到外部数据源来扩展模型的知识范围。
基础 RAG 流程
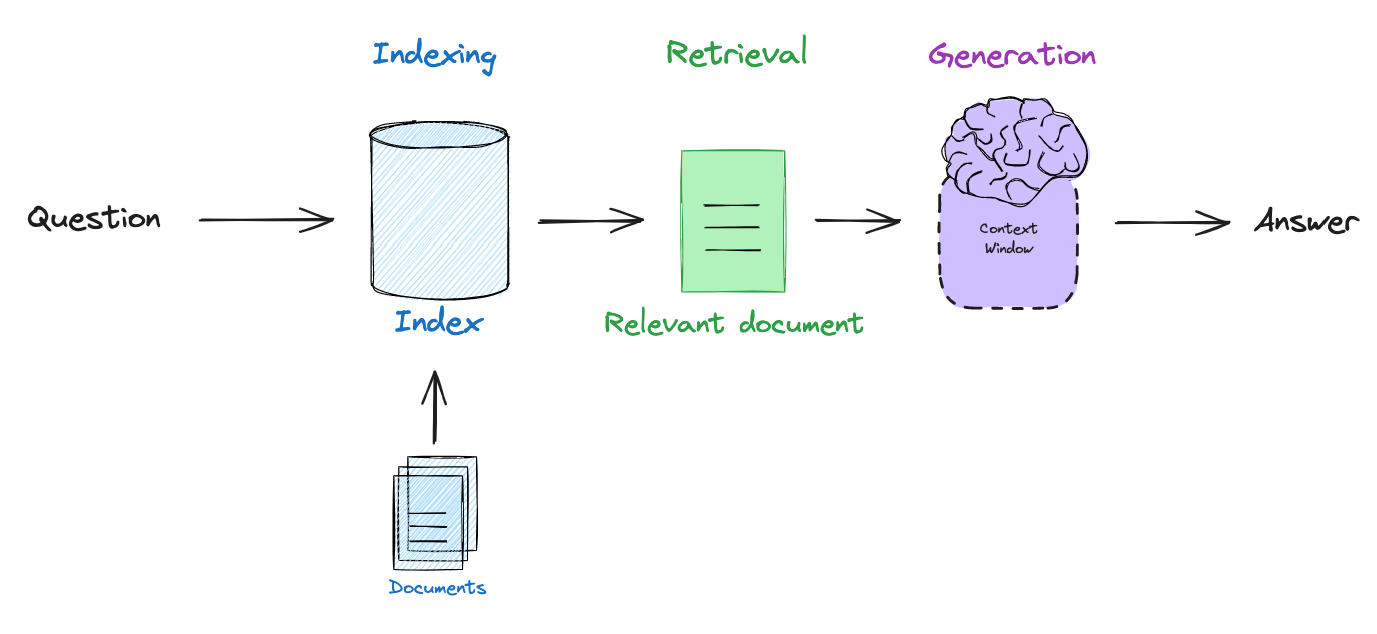
基础 RAG 管道遵循以下步骤:
- 嵌入用户查询 - 将用户问题转换为向量
- 检索相关文档 - 从向量数据库中查找相似文档
- 生成回答 - 将检索到的文档传递给 LLM,生成基于上下文的答案
二、自反思 RAG (Self-Reflective RAG)
自反思 RAG 涉及围绕检索步骤的逻辑推理。核心问题包括:
- 何时检索? - 是否需要检索外部信息
- 是否重写查询? - 当前查询能否获得更好的结果
- 何时丢弃文档? - 检索到的文档是否相关,是否需要重试
RAG 的三种认知架构
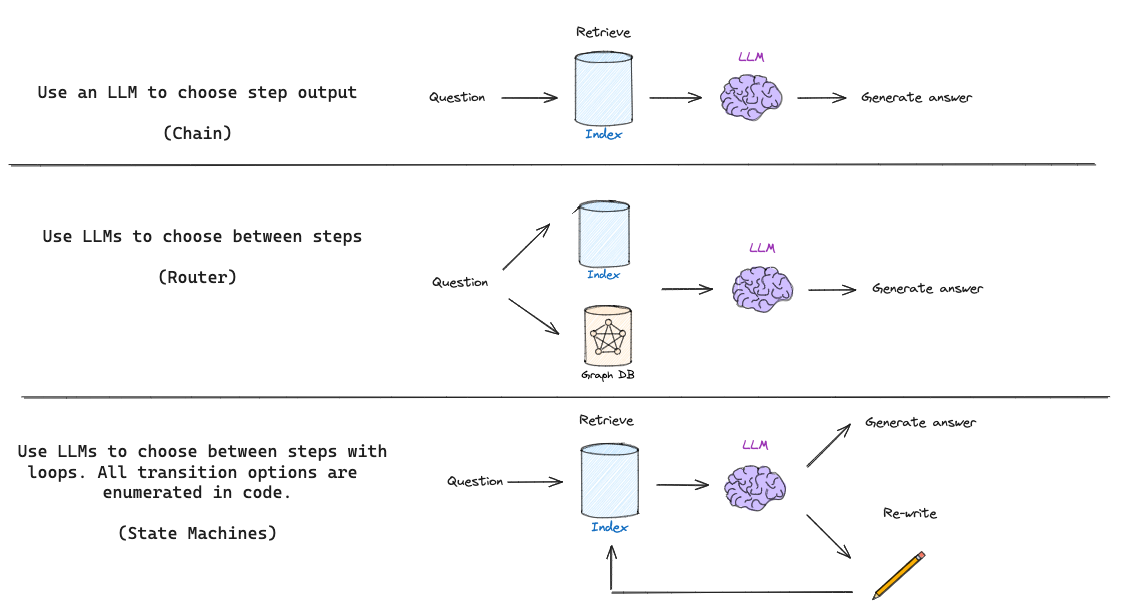
| 架构类型 | 描述 |
|---|---|
| Chain (链式) | LLM 基于检索到的文档生成答案 |
| Routing (路由) | LLM 根据问题选择不同的检索器 |
| State Machines (状态机) | 定义步骤(检索、文档评分、查询重写)和它们之间的条件转换 |
"状态机让我们能够定义一组步骤(例如:检索、评估文档、重写查询)并设置它们之间的转换选项。"
状态机设计
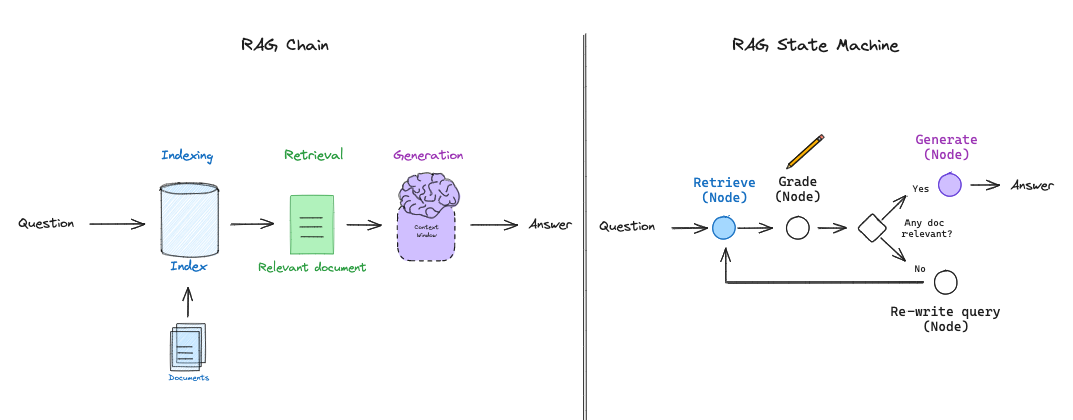
LangGraph 使我们能够实现 LLM 状态机,从而设计灵活的 RAG 流程。下面我们将通过两种当代研究方法来演示这一点。
三、CRAG (Corrective RAG)
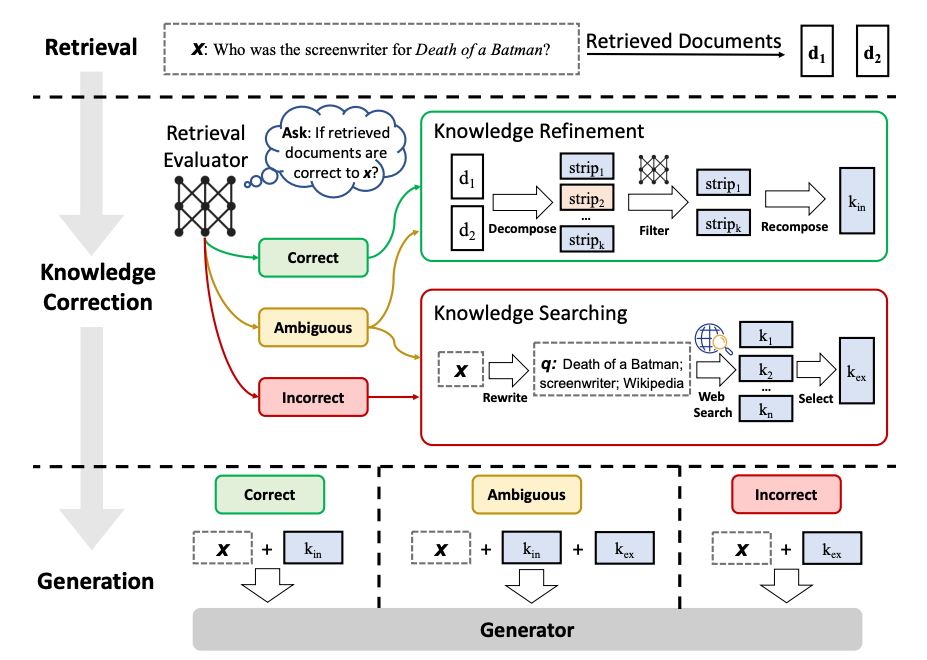
CRAG (Corrective RAG) 是一种纠正性检索增强生成方法,引入了三个关键机制:
3.1 CRAG 的三大机制
| 机制 | 功能 |
|---|---|
| 检索评估器 (Retrieval Evaluator) | 评估检索到的文档质量,进行置信度评分 |
| 网络搜索补充 (Web-based Supplementation) | 当向量库检索不明确或不相关时,使用网络搜索作为补充 |
| 知识细化 (Knowledge Refinement) | 将文档分割成"知识条",逐个评分,过滤不相关内容 |
3.2 LangGraph 实现 CRAG
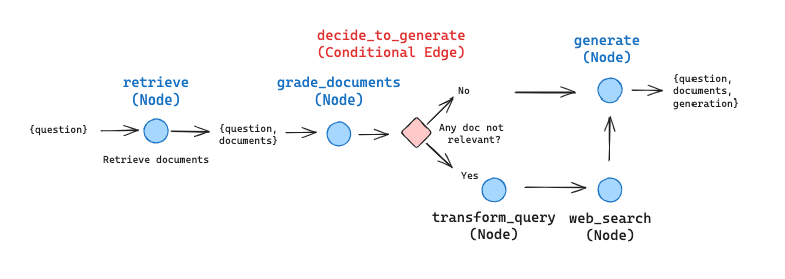
我们对 CRAG 进行了简化实现:
- 跳过知识细化阶段 - 初始版本先不实现
- 网络搜索补充 - 如果任何文档不相关,则使用网络搜索
- 查询重写 - 优化网络搜索的查询
- Pydantic 模型 - 使用结构化输出进行二元决策
from typing import Literal
from pydantic import BaseModel, Field
class GradeDocuments(BaseModel):
"""对检索到的文档进行相关性评分"""
binary_score: Literal["yes", "no"] = Field(
description="文档是否与问题相关,'yes' 或 'no'"
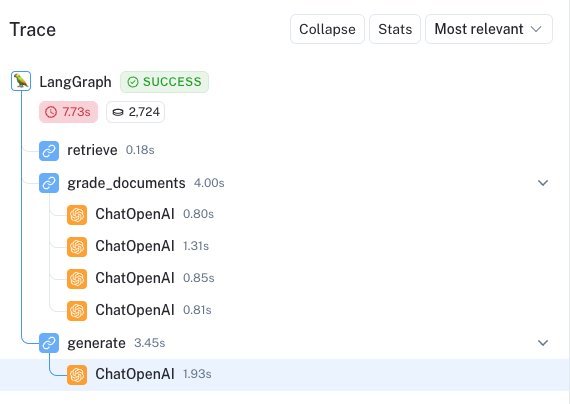
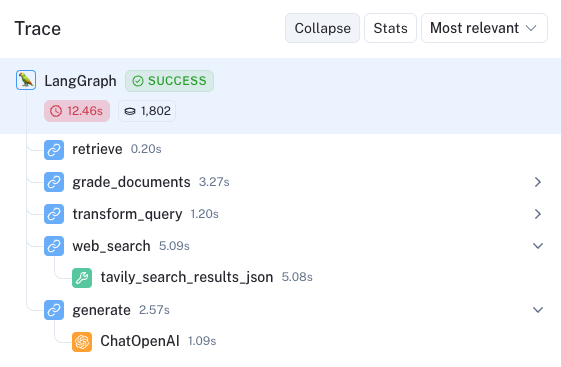
)3.3 CRAG 执行追踪
以下是 CRAG 系统的实际执行追踪示例:
四、Self-RAG 框架
Self-RAG 训练 LLM 生成自反思令牌 (Self-reflection Tokens),用于控制 RAG 的各个阶段。
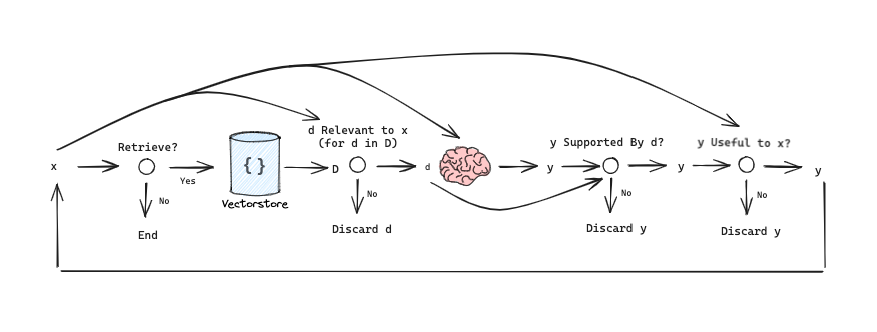
4.1 Self-RAG 的四种令牌

| 令牌类型 | 功能 | 输入 | 输出 |
|---|---|---|---|
| Retrieve | 决定是否检索文档块 | 问题,或问题 + 生成内容 | yes, no, continue |
| ISREL | 评估段落与问题的相关性 | 问题,文档块 | relevant, irrelevant |
| ISSUP | 评估生成内容是否被文档块支持 | 问题,文档块,生成内容 | fully supported, partially supported, no support |
| ISUSE | 评估生成内容对回答问题的有用程度 | 问题,生成内容 | 5, 4, 3, 2, 1 |
4.2 Self-RAG 流程图
4.3 LangGraph 实现 Self-RAG
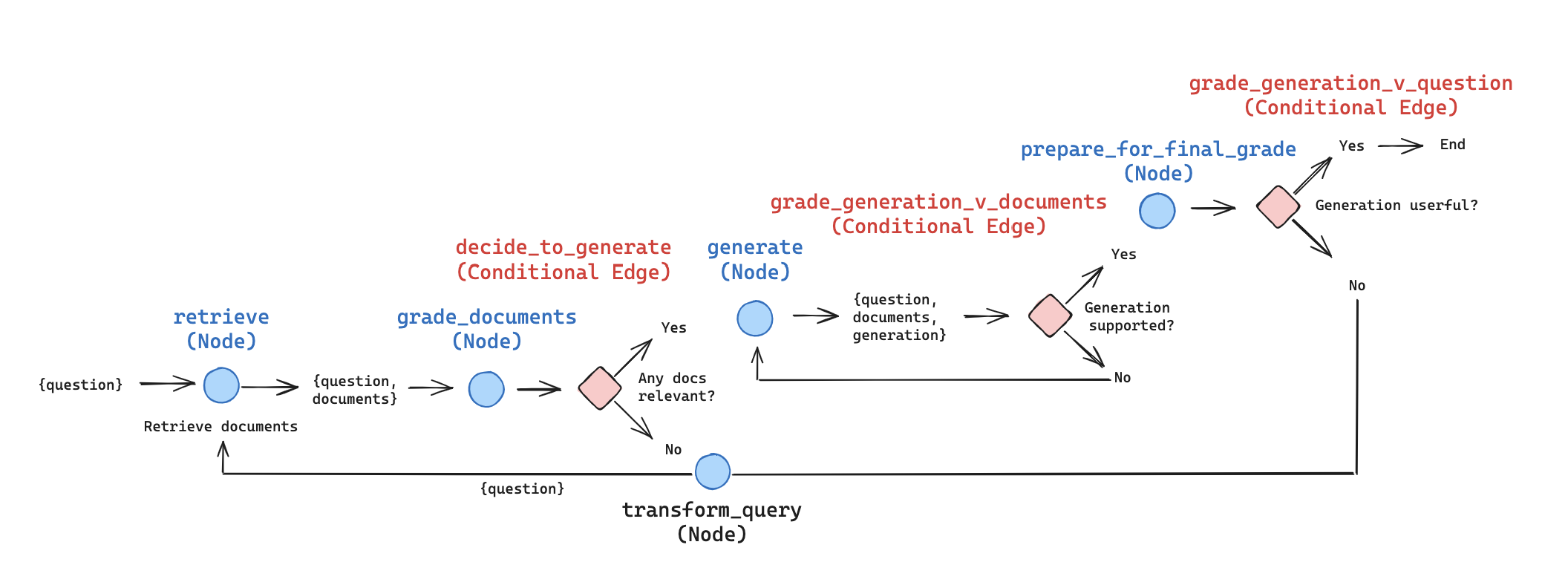
简化实现包括:
- 文档评分 (Document Grading) - 如果所有检索到的文档都不相关,查询重构触发重新检索
- 合并生成 (Consolidated Generation) - 从所有相关文档生成单个回答(而不是按文档块生成)
- 双重评分 (Dual Grading) - 生成内容同时针对文档(防止幻觉)和整体有用性进行评估
class GraphState(TypedDict):
"""图状态定义"""
question: str # 用户问题
generation: str # LLM 生成的回答
documents: List[str] # 检索到的文档列表五、Self-RAG 实际示例
以下是 Self-RAG 自我纠正能力的实际演示:
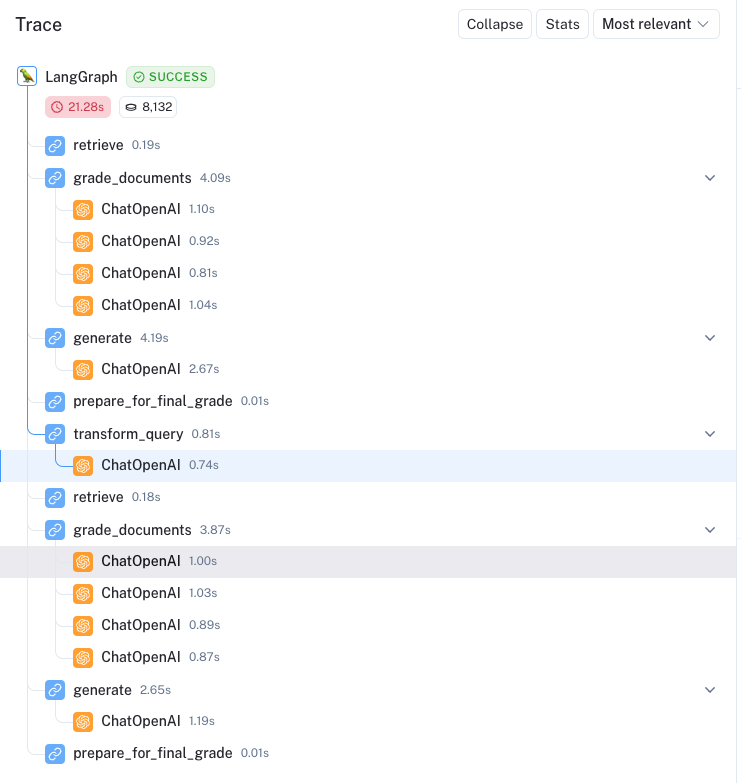
示例:代理记忆类型问题
用户问题: "Explain how the different types of agent memory work?" (解释不同类型的代理记忆是如何工作的?)
第一轮:
- 所有检索到的文档看起来都相关
- 但生成的内容未通过有用性检查
- 系统自动重构查询
查询重写: "How do the various types of agent memory function?" (各种类型的代理记忆是如何运作的?)
第二轮:
- 重新检索文档
- 过滤掉一个不相关的文档
- 生成新的回答
最终回答:
"The various types of agent memory include sensory memory, short-term memory, and long-term memory. Sensory memory retains impressions of sensory information for a few seconds. Short-term memory is utilized for in-context learning and prompt engineering. Long-term memory allows the agent to retain and recall information over extended periods."
(各种类型的代理记忆包括感觉记忆、短期记忆和长期记忆。感觉记忆在几秒钟内保留感觉信息的印象。短期记忆用于上下文学习和提示工程。长期记忆使代理能够在较长时间内保留和回忆信息。)
该回答成功通过了两项检查:
- 支持性检查 - 内容被文档支持,无幻觉
- 有用性检查 - 内容对回答问题有帮助
六、总结
"自反思可以极大地增强 RAG,实现对低质量检索或生成内容的纠正。"
关键要点
- 自反思机制 - 通过评估检索质量和生成质量,系统可以自我纠正
- LangGraph 的优势 - 提供"流程工程"能力,便于实现研究论文中的高级 RAG 概念
- 清晰的审计追踪 - 每一步决策都可追溯,便于调试和优化
技术栈
| 组件 | 用途 |
|---|---|
| LangGraph | 图结构智能体编排 |
| OpenAI Function Calling | 结构化输出,确保一致的二元逻辑 |
| Tavily Search API | 网络搜索集成 |
| LangSmith | 执行追踪和调试 |
参考资源
本文内容基于 LangChain 官方博客,翻译并整理为教程格式。