LangGraph 完整系统集成详细解读
📚 概述
本章将前面所有组件整合为完整的端到端 Deep Research 系统。包括需求澄清、研究规划、并行研究、最终报告生成的完整流程。
完整流程:
用户输入
↓
Scoping (9.1)
├─ 需求澄清
└─ 研究简报生成
↓
Multi-Agent Research (9.2-9.4)
├─ Supervisor 决策
├─ 并行 Research Agents
└─ 结果聚合
↓
Report Generation (本章新增)
└─ 综合所有发现生成最终报告
↓
输出最终报告🔧 核心组件集成
1. 最终报告生成节点
python
from langchain.chat_models import init_chat_model
writer_model = init_chat_model(
model="openai:gpt-4.1",
max_tokens=32000 # 允许长报告
)
async def final_report_generation(state: AgentState):
"""
生成最终研究报告
输入:
- research_brief: 原始研究主题
- notes: 所有 Agent 的压缩研究结果
- raw_notes: 详细的原始笔记
输出:
- final_report: 结构化的最终报告
"""
# 获取所有研究发现
notes = state.get("notes", [])
findings = "\n\n".join(notes)
# 生成报告的 Prompt
final_report_prompt = f"""
你是一个专业的研究报告撰写专家。
原始研究主题:
{state.get("research_brief", "")}
研究发现:
{findings}
今天的日期: {get_today_str()}
请基于上述研究发现,生成一份结构化的研究报告,包括:
1. **执行摘要** (2-3 段)
- 研究目的概述
- 核心发现总结
- 关键结论
2. **详细发现** (按主题组织)
- 使用标题和子标题
- 引用具体数据和来源
- 提供证据链
3. **综合分析**
- 交叉验证发现
- 识别模式和趋势
- 指出差异和共识
4. **结论与建议**
- 回答原始研究问题
- 提供可操作建议
5. **来源列表**
- 列出所有引用的来源
使用 Markdown 格式,确保专业、清晰、全面。
"""
# 生成报告
response = await writer_model.ainvoke([
HumanMessage(content=final_report_prompt)
])
return {
"final_report": response.content,
"messages": [
AIMessage(content=f"研究完成!以下是最终报告:\n\n{response.content}")
]
}关键点:
- 使用
max_tokens=32000允许长报告 - Prompt 明确指定报告结构
- 引用原始研究主题保持聚焦
2. 完整图构建
python
from langgraph.graph import StateGraph, START, END
# 导入之前构建的组件
from deep_research_from_scratch.research_agent_scope import (
clarify_with_user,
write_research_brief
)
from deep_research_from_scratch.multi_agent_supervisor import supervisor_agent
# 构建完整工作流
deep_researcher_builder = StateGraph(AgentState, input_schema=AgentInputState)
# 添加节点
deep_researcher_builder.add_node("clarify_with_user", clarify_with_user)
deep_researcher_builder.add_node("write_research_brief", write_research_brief)
deep_researcher_builder.add_node("supervisor_subgraph", supervisor_agent) # 子图!
deep_researcher_builder.add_node("final_report_generation", final_report_generation)
# 添加边(线性流程)
deep_researcher_builder.add_edge(START, "clarify_with_user")
deep_researcher_builder.add_edge("write_research_brief", "supervisor_subgraph")
deep_researcher_builder.add_edge("supervisor_subgraph", "final_report_generation")
deep_researcher_builder.add_edge("final_report_generation", END)
# 编译
agent = deep_researcher_builder.compile()
# 🎨 可视化图结构
from IPython.display import Image, display
display(Image(agent.get_graph().draw_mermaid_png()))完整系统架构图:
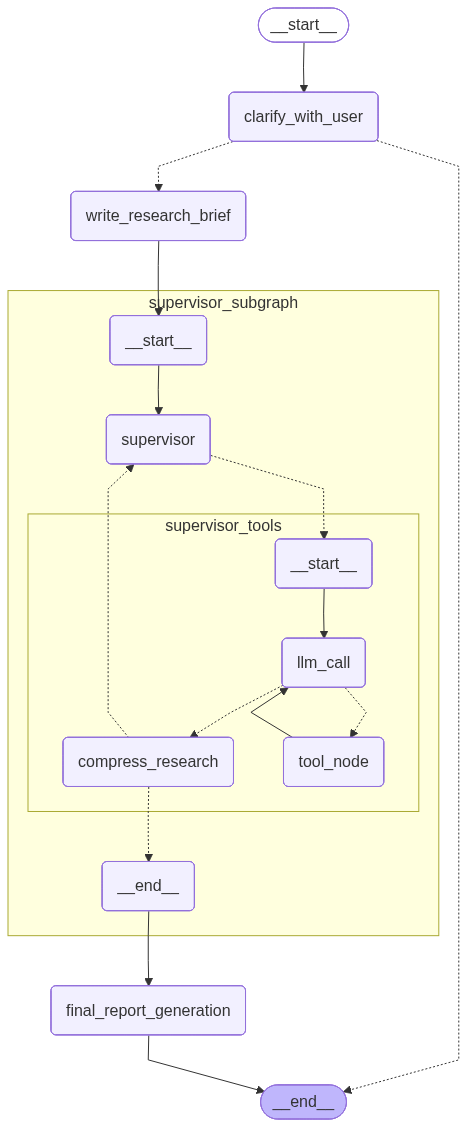
关键技术:子图集成
python
# supervisor_agent 本身就是一个完整的图
supervisor_agent = supervisor_builder.compile()
# 将其作为节点添加到主图中
deep_researcher_builder.add_node("supervisor_subgraph", supervisor_agent)好处:
- 模块化 - 每个组件独立开发和测试
- 可重用 - supervisor_agent 可以单独使用
- 清晰 - 主图只关注高层流程
⚙️ 关键配置
1. 递归限制配置
问题: LangGraph 默认递归限制是 25 步,复杂研究任务可能超出。
python
# 计算步骤数
Scoping:
- clarify_with_user: 1 步
- (可能的用户交互): 1-2 轮
- write_research_brief: 1 步
Supervisor:
- supervisor: 1 步
- supervisor_tools: 1 步
- (可能多轮): 2-3 轮
每个 Research Agent (假设 3 个并行):
- llm_call: 2-3 次
- tool_node: 2-3 次
- compress_research: 1 次
每个 Agent: 6-8 步
Final Report:
- final_report_generation: 1 步
总计: 可能达到 30-40 步解决方案:提高递归限制
python
# 在 invoke 时配置
thread = {
"configurable": {
"thread_id": "1",
"recursion_limit": 50 # 提高到 50
}
}
result = await agent.ainvoke(
{"messages": [HumanMessage(content="...")]},
config=thread
)2. Checkpointer 配置(可选)
python
from langgraph.checkpoint.memory import MemorySaver
# 用于支持中断和恢复
checkpointer = MemorySaver()
agent = deep_researcher_builder.compile(
checkpointer=checkpointer
)
# 现在支持:
# - 中断后恢复
# - 查看中间状态
# - 时间旅行调试🎭 完整执行示例
示例:对比 Gemini vs OpenAI Deep Research
python
thread = {"configurable": {"thread_id": "1", "recursion_limit": 50}}
# 第一次调用:模糊请求
result = await agent.ainvoke({
"messages": [HumanMessage(content="Compare Gemini to OpenAI Deep Research")]
}, config=thread)
# Scoping 澄清
print(result['messages'][-1].content)
# 输出: "Could you clarify what you mean by 'OpenAI Deep Research'?
# Are you referring to a specific product or feature?"
# 第二次调用:提供澄清
result = await agent.ainvoke({
"messages": [HumanMessage(content="The specific Deep Research products")]
}, config=thread)
# 完整执行
print(result['final_report'])执行流程(详细):
Step 1-2: Scoping
├─ clarify_with_user
│ └─ 检测到 "Deep Research" 需要澄清
│ └─ 返回问题给用户
├─ (用户提供澄清)
└─ write_research_brief
└─ 生成: "对比 Gemini 和 OpenAI Deep Research 产品的功能、性能、使用体验..."
Step 3-20: Multi-Agent Research
├─ supervisor (Step 3)
│ └─ 决策: "这是对比任务,需要 2 个并行 Agent"
│ └─ 调用: ConductResearch(Gemini) + ConductResearch(OpenAI)
│
├─ supervisor_tools (Step 4)
│ └─ 并行启动 2 个 Research Agents
│
├─ Agent A: Gemini 研究 (Step 5-12)
│ ├─ llm_call (Step 5)
│ ├─ tool_node: Search "Gemini Deep Research" (Step 6)
│ ├─ llm_call (Step 7)
│ ├─ tool_node: think_tool (Step 8)
│ ├─ llm_call (Step 9)
│ ├─ tool_node: Search "Gemini features" (Step 10)
│ ├─ llm_call (Step 11)
│ └─ compress_research (Step 12)
│
├─ Agent B: OpenAI 研究 (Step 5-12, 并行)
│ └─ (类似流程)
│
└─ supervisor (Step 13)
└─ 决策: "有足够信息,调用 ResearchComplete"
Step 21: Final Report
└─ final_report_generation
└─ 生成结构化报告
总步骤: 约 21-25 步💡 性能优化
1. 模型选择策略
| 组件 | 推荐模型 | 原因 |
|---|---|---|
| Scoping | GPT-4.1 | 需要推理能力 |
| Research LLM | Claude Sonnet 4 | 深度分析能力强 |
| Compression | GPT-4.1 | 速度快,成本低 |
| Report | GPT-4.1 | 写作能力强,输出快 |
成本示例(单次研究):
Scoping: $0.05 (2 次 LLM 调用)
Research (3 个 Agent, 每个 5 次调用): $0.60
Compression (3 次): $0.15
Report: $0.10
总计: ~$0.902. 缓存策略
python
from functools import lru_cache
@lru_cache(maxsize=100)
def cached_search(query: str):
"""缓存搜索结果"""
return tavily_search.invoke({"query": query})3. 并行优化
python
# 如果 Supervisor 决定 3 个 Agent
# 串行: 3 * 30s = 90s
# 并行: max(30s, 30s, 30s) = 30s
# 加速比: 3x🎓 部署考虑
1. LangGraph Studio 本地调试
bash
# 从项目根目录运行
uvx --refresh --from "langgraph-cli[inmem]" --with-editable . --python 3.11 langgraph dev --allow-blockinglanggraph.json 配置:
json
{
"graphs": {
"research_agent_full": "./src/deep_research_from_scratch/research_agent_full.py:agent"
},
"dependencies": ["."],
"env": ".env"
}2. LangGraph Platform 部署
python
# 使用持久化 Checkpointer
from langgraph.checkpoint.postgres import PostgresSaver
checkpointer = PostgresSaver(
connection_string="postgresql://user:pass@host:port/db"
)
agent = deep_researcher_builder.compile(
checkpointer=checkpointer
)3. API 部署
python
from fastapi import FastAPI
from langserve import add_routes
app = FastAPI(title="Deep Research API")
# 添加路由
add_routes(
app,
agent,
path="/research",
enable_feedback_endpoint=True,
enable_public_trace_link_endpoint=True
)🔍 调试技巧
1. 查看中间状态
python
# 使用 Checkpointer
result = agent.invoke(input, config=thread)
# 查看历史
history = agent.get_state_history(thread)
for state in history:
print(f"Step: {state.metadata}")
print(f"Messages: {len(state.values['messages'])}")2. 单步调试
python
# 单独测试每个组件
scoping_result = scope_research.invoke(input, config=thread)
print("Scoping result:", scoping_result)
supervisor_result = supervisor_agent.invoke({
"supervisor_messages": [HumanMessage(scoping_result["research_brief"])]
})
print("Research result:", supervisor_result)3. 日志输出
python
import logging
logging.basicConfig(level=logging.INFO)
# 在节点中添加日志
def llm_call(state):
logging.info(f"LLM call with {len(state['messages'])} messages")
result = model.invoke(...)
logging.info(f"LLM returned {len(result.tool_calls)} tool calls")
return {"messages": [result]}💡 最佳实践总结
1. 模块化设计
python
# ✅ 每个组件独立
scoping = scope_builder.compile()
supervisor = supervisor_builder.compile()
full_system = full_builder.compile()
# 可以单独测试和优化每个组件2. 错误处理
python
async def safe_invoke(agent, input, config):
try:
return await agent.ainvoke(input, config)
except RecursionError:
# 递归限制错误
config["configurable"]["recursion_limit"] = 100
return await agent.ainvoke(input, config)
except Exception as e:
# 其他错误
return {"error": str(e)}3. 性能监控
python
import time
async def timed_invoke(agent, input, config):
start = time.time()
result = await agent.ainvoke(input, config)
duration = time.time() - start
print(f"Total time: {duration:.2f}s")
print(f"Cost estimate: ${estimate_cost(result):.2f}")
return result🚀 下一步
完成本节,你已经掌握了完整 Deep Research 系统的构建。
下一章:9.6 小结和复习 - 回顾所有核心概念,总结最佳实践,讨论生产部署的关键考虑!