LangGraph Chain 详细解读
网站使用说明
📚 概述
本文档详细解读 LangGraph 的 Chain(链式调用) 基础概念。这是 LangGraph 开发的第一课,涵盖了构建智能对话系统的核心组件:消息系统、聊天模型、工具绑定和工具执行。通过本教程,你将掌握如何使用 LangChain 的基础概念构建一个简单但功能完整的 AI 链。
📚 术语表
| 术语名称 | LangGraph 定义和解读 | Python 定义和说明 | 重要程度 |
|---|---|---|---|
| MessagesState | LangGraph 预定义的消息状态类,专门用于管理对话历史 | TypedDict 子类,包含 messages 字段并自动使用 add_messages reducer | ⭐⭐⭐⭐⭐ |
| add_messages | 智能消息合并函数,支持追加和基于 ID 的更新 | Reducer 函数,自动追加新消息到列表,相同 ID 的消息会被替换 | ⭐⭐⭐⭐⭐ |
| Reducer | 控制状态字段更新方式的函数,避免默认覆盖行为 | 接收旧值和新值两个参数,返回合并后的值 | ⭐⭐⭐⭐⭐ |
| Annotated | Python 类型注解增强工具,为类型添加元数据 | typing 模块的类型,用于在类型注解中附加额外信息如 Reducer | ⭐⭐⭐⭐ |
| HumanMessage | 表示用户输入的消息类型 | LangChain 消息类,包含 content、name 等属性 | ⭐⭐⭐⭐⭐ |
| AIMessage | 表示 AI 模型响应的消息类型 | LangChain 消息类,可包含 content、tool_calls 等属性 | ⭐⭐⭐⭐⭐ |
| ToolMessage | 表示工具执行结果的消息类型 | LangChain 消息类,包含 content 和 tool_call_id 属性 | ⭐⭐⭐⭐⭐ |
| bind_tools() | 将 Python 函数绑定为 LLM 可调用的工具 | ChatModel 方法,自动从函数签名生成工具 schema | ⭐⭐⭐⭐⭐ |
| tool_calls | AIMessage 中存储的工具调用请求信息 | 列表属性,包含工具名称、参数和调用 ID | ⭐⭐⭐⭐⭐ |
| Docstring | 函数的文档字符串,LLM 用于理解工具用途 | Python 三引号字符串,LangChain 解析为工具描述 | ⭐⭐⭐⭐ |
| Type Hints | 函数的类型注解,定义参数和返回值类型 | Python 类型系统,帮助 LangChain 生成工具参数 schema | ⭐⭐⭐⭐ |
🎯 核心概念
什么是 Chain?
在 LangChain/LangGraph 中,Chain 是一系列按顺序执行的操作组合。一个简单的 Chain 通常包含:
- 输入处理:接收用户消息
- 模型调用:使用 LLM 生成响应
- 工具执行(可选):调用外部工具/函数
- 输出返回:返回最终结果
本教程的四大核心概念
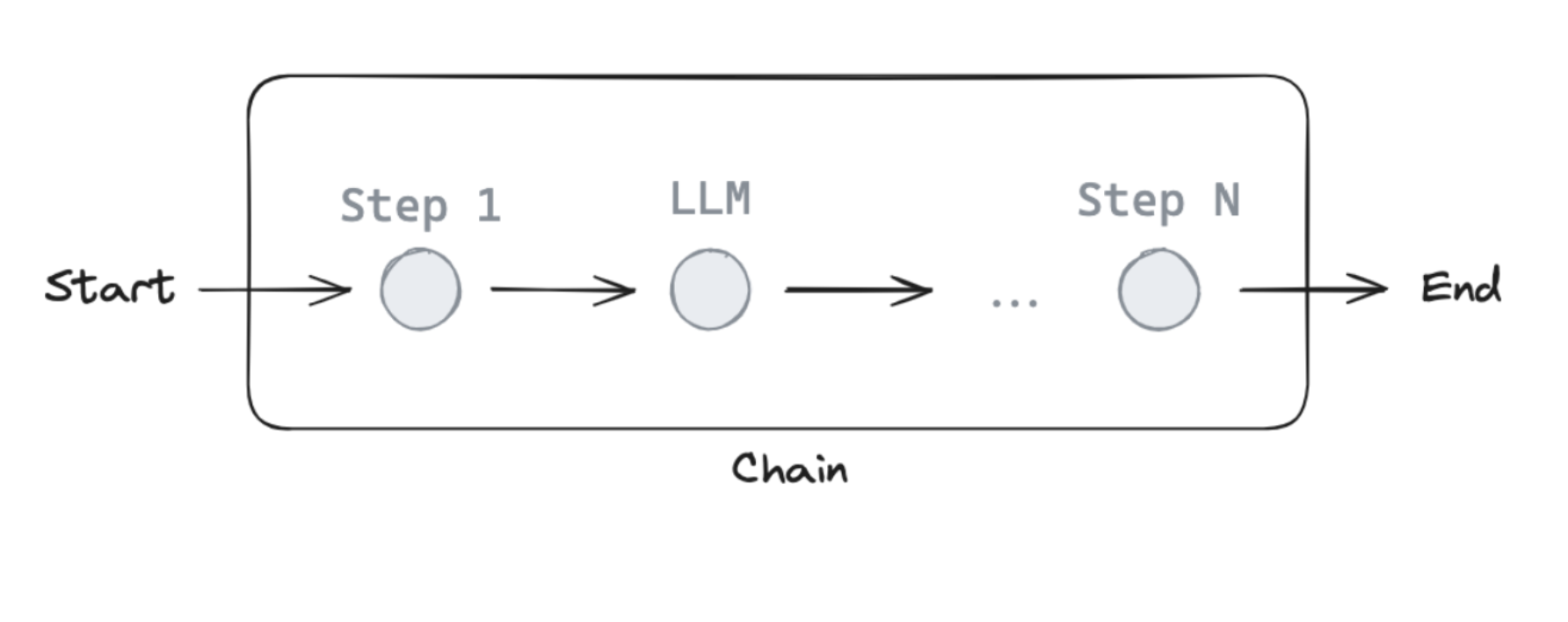
- 消息(Messages):使用聊天消息作为图状态
- 聊天模型(Chat Models):在图节点中使用 LLM
- 工具绑定(Tool Binding):为聊天模型绑定工具
- 工具执行(Tool Calling):在图节点中执行工具调用
系统架构图
用户输入 "Multiply 2 and 3"
↓
[tool_calling_llm]
↓
检测到需要调用工具
↓
返回工具调用信息
(工具名: multiply, 参数: {a:2, b:3})🔧 代码实现详解
1. 消息系统(Messages)
什么是消息?
聊天模型使用 消息(Messages) 来表示对话中的不同角色。LangChain 支持多种消息类型:
| 消息类型 | 角色 | 用途 |
|---|---|---|
HumanMessage | 用户 | 表示用户输入 |
AIMessage | AI 模型 | 表示模型响应 |
SystemMessage | 系统 | 指导模型行为 |
ToolMessage | 工具 | 工具调用的结果 |
消息的组成部分
每个消息可以包含:
content(必需):消息内容name(可选):消息发送者的名字response_metadata(可选):元数据字典(如模型响应信息)
代码示例
from langchain_core.messages import AIMessage, HumanMessage
# 创建消息列表
messages = [
AIMessage(content="So you said you were researching ocean mammals?", name="Model"),
HumanMessage(content="Yes, that's right.", name="Lance"),
AIMessage(content="Great, what would you like to learn about.", name="Model"),
HumanMessage(content="I want to learn about the best place to see Orcas in the US.", name="Lance")
]
# 打印消息
for m in messages:
m.pretty_print()输出:
================================== Ai Message ==================================
Name: Model
So you said you were researching ocean mammals?
================================ Human Message =================================
Name: Lance
Yes, that's right.
...Python 知识点:for 循环与方法调用
for m in messages:
m.pretty_print()for m in messages:遍历messages列表中的每个元素m.pretty_print():调用每个消息对象的pretty_print()方法- 这是 Python 面向对象编程的典型用法
2. 聊天模型(Chat Models)
什么是聊天模型?
聊天模型 是支持对话式交互的 LLM,可以:
- 接收消息列表作为输入
- 理解对话上下文
- 生成符合角色的回复
LangChain 支持多种聊天模型提供商:OpenAI、Anthropic、Google、Ollama 等。
设置 API Key
import os, getpass
def _set_env(var: str):
if not os.environ.get(var):
os.environ[var] = getpass.getpass(f"{var}: ")
_set_env("OPENAI_API_KEY")Python 知识点:环境变量与安全性
os.environ.get(var):获取环境变量getpass.getpass():安全地输入密码(输入不会显示)- 这是保护 API Key 的最佳实践
使用聊天模型
from langchain_openai import ChatOpenAI
# 初始化模型
llm = ChatOpenAI(model="gpt-5-nano")
# 调用模型
result = llm.invoke(messages)输出类型:
type(result)
# langchain_core.messages.ai.AIMessageresult 是一个 AIMessage 对象,包含:
result.content # AI 生成的文本内容
result.response_metadata # 响应元数据响应元数据详解
result.response_metadata输出示例:
{
'token_usage': {
'completion_tokens': 228, # 输出的 token 数
'prompt_tokens': 67, # 输入的 token 数
'total_tokens': 295 # 总 token 数
},
'model_name': 'gpt-5-nano-2024-08-06',
'finish_reason': 'stop', # 停止原因(正常结束)
'logprobs': None
}重要性:
- 可以跟踪 API 使用成本
- 了解模型生成的详细信息
- 调试和优化性能
3. 工具(Tools)
什么是工具?
工具(Tools) 允许 LLM 与外部系统交互。当你需要:
- 调用 API
- 执行计算
- 查询数据库
- 访问外部服务
你可以将这些功能定义为"工具",让模型知道何时以及如何使用它们。
工具的工作原理
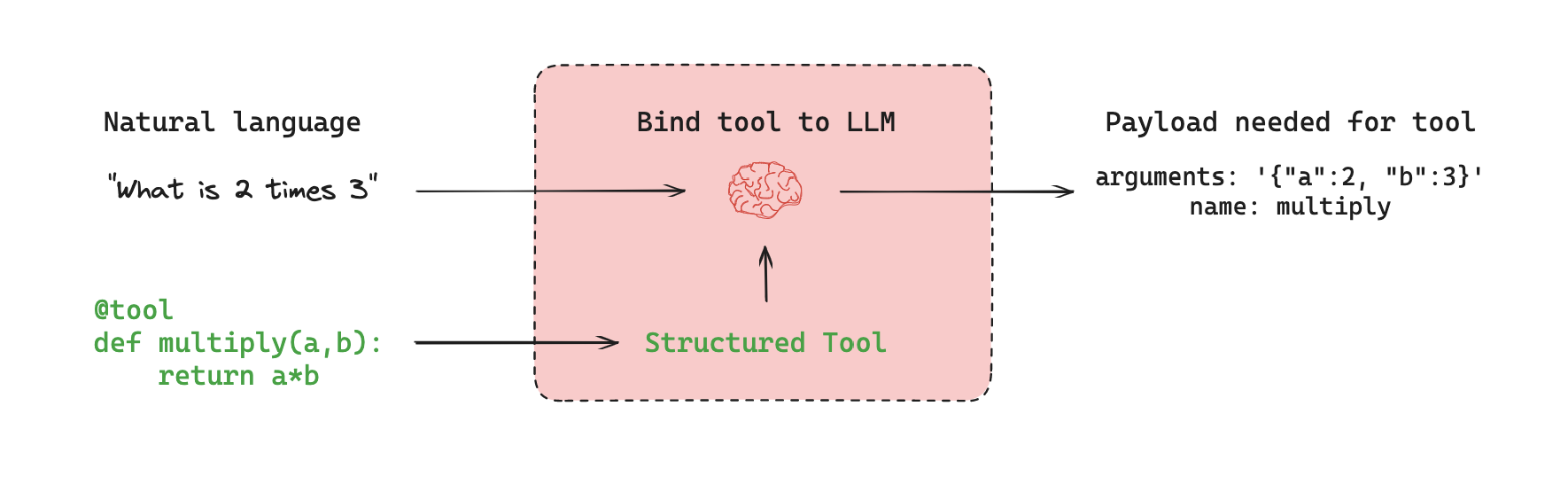
流程说明:
用户输入(自然语言)
↓
LLM 分析输入
↓
决定是否需要调用工具
↓
返回符合工具 schema 的调用信息
(包含工具名称和参数)定义工具
在 LangChain 中,任何 Python 函数都可以作为工具!
def multiply(a: int, b: int) -> int:
"""Multiply a and b.
Args:
a: first int
b: second int
"""
return a * b关键要点:
- 类型注解:
a: int, b: int -> int让模型知道参数类型 - 文档字符串:描述函数的功能,帮助模型理解何时使用
Python 知识点:类型注解(Type Hints)
def multiply(a: int, b: int) -> int:
# ^^^^^^ ^^^^^^ ^^^
# 参数a 参数b 返回值
# 是int 是int 是int
return a * b类型注解的作用:
- 提供 IDE 代码提示
- 帮助 LangChain 生成工具 schema
- 提高代码可读性
- 不强制执行(Python 仍然是动态类型语言)
绑定工具到模型
llm_with_tools = llm.bind_tools([multiply])发生了什么?
bind_tools()告诉模型:"你可以调用这些工具"- LangChain 自动从函数签名生成工具 schema
- 模型现在知道
multiply工具的存在、参数和用途
工具调用示例
tool_call = llm_with_tools.invoke([
HumanMessage(content="What is 2 multiplied by 3", name="Lance")
])
tool_call.tool_calls输出:
[{
'name': 'multiply', # 工具名称
'args': {'a': 2, 'b': 3}, # 工具参数
'id': 'call_lBBBNo5oYpHGRqwxNaNRbsiT', # 调用 ID
'type': 'tool_call' # 类型
}]重要理解:
- LLM 并没有真正执行
multiply(2, 3) - 它只是 返回了调用信息
- 实际执行需要在后续步骤中处理
4. 使用消息作为状态(Messages as State)
为什么使用消息作为状态?
在对话系统中,我们需要:
- 保存对话历史
- 追踪多轮交互
- 传递上下文信息
使用 消息列表 作为图状态是最自然的方式。
定义状态
方法 1:手动定义
from typing_extensions import TypedDict
from langchain_core.messages import AnyMessage
class MessagesState(TypedDict):
messages: list[AnyMessage]Python 知识点:TypedDict
TypedDict 是 Python 的类型注解工具,用于定义字典的结构:
class MessagesState(TypedDict):
messages: list[AnyMessage]
# ^^^^^^^^^^^^^^^^
# 值的类型:AnyMessage 对象的列表
# 使用
state = {"messages": [HumanMessage(content="Hi")]}优势:
- 提供 IDE 类型检查和自动补全
- 清晰地定义数据结构
- 不影响运行时性能(仅用于静态分析)
5. Reducers(归约器)⭐
问题:状态覆盖
默认情况下,节点返回的新值会 覆盖 旧值:
# 初始状态
state = {"messages": [message1, message2]}
# 节点返回
node_output = {"messages": [message3]}
# 结果:message1 和 message2 被丢弃!
new_state = {"messages": [message3]}这不是我们想要的! 我们希望 追加 消息,而不是覆盖。
解决方案:add_messages Reducer
Reducer 是一个函数,指定如何更新状态。
from typing import Annotated
from langgraph.graph.message import add_messages
class MessagesState(TypedDict):
messages: Annotated[list[AnyMessage], add_messages]
# ^^^^^^^^^ ^^^^^^^^^^^^^
# 基础类型 Reducer 函数Python 知识点:Annotated
Annotated 是 Python 3.9+ 引入的类型注解增强工具:
from typing import Annotated
Annotated[类型, 元数据1, 元数据2, ...]
# ^^^^ ^^^^^^^^^^^^^^^^^^^^^^^^
# 基础 额外信息(不影响类型检查)在 LangGraph 中:
messages: Annotated[list[AnyMessage], add_messages]
# ^^^^^^^^^^^^^^^^^ ^^^^^^^^^^^^^
# 类型:消息列表 元数据:reducer 函数LangGraph 会读取这个元数据,知道应该使用 add_messages 来更新状态。
add_messages 的工作原理
from langgraph.graph.message import add_messages
# 初始消息
initial = [
AIMessage(content="Hello! How can I assist you?", name="Model"),
HumanMessage(content="I'm looking for information on marine biology.", name="Lance")
]
# 新消息
new_message = AIMessage(content="Sure, I can help with that.", name="Model")
# 使用 add_messages
result = add_messages(initial, new_message)
# 结果:[message1, message2, message3] ← 追加,不覆盖!add_messages 的特性:
- 自动追加新消息到列表末尾
- 支持单个消息或消息列表
- 处理消息去重(基于 ID)
- 是 LangGraph 内置的 reducer
6. 使用 MessagesState(推荐方式)
由于"消息列表"是如此常见的状态结构,LangGraph 提供了预构建的 MessagesState:
from langgraph.graph import MessagesState
class MessagesState(MessagesState):
# 如果需要额外字段,在这里添加
pass预构建的 MessagesState 包含:
messages字段:list[AnyMessage]- 自动使用
add_messagesreducer - 无需手动定义
如果需要额外字段:
class ExtendedState(MessagesState):
user_id: str
session_id: str
# messages 字段已经自动包含7. 构建图
现在我们有了所有组件,可以构建图了!
from langgraph.graph import StateGraph, START, END
# 定义节点
def tool_calling_llm(state: MessagesState):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
# 构建图
builder = StateGraph(MessagesState)
builder.add_node("tool_calling_llm", tool_calling_llm)
builder.add_edge(START, "tool_calling_llm")
builder.add_edge("tool_calling_llm", END)
graph = builder.compile()完整案例代码(可直接运行)
以下是完整的可运行代码,包含所有必要的导入和定义:
## 完整案例代码
import os
from typing import Annotated
from typing_extensions import TypedDict
from IPython.display import Image, display
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_core.messages import AnyMessage, HumanMessage, AIMessage
# 定义状态(使用 add_messages reducer)
class MessagesState(TypedDict):
messages: Annotated[list[AnyMessage], add_messages]
# 定义工具
def multiply(a: int, b: int) -> int:
"""Multiply a and b.
Args:
a: first int
b: second int
"""
return a * b
# 初始化模型并绑定工具(需要设置 OPENAI_API_KEY)
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")
llm_with_tools = llm.bind_tools([multiply])
# 定义节点
def tool_calling_llm(state: MessagesState):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
# 构建图
builder = StateGraph(MessagesState)
builder.add_node("tool_calling_llm", tool_calling_llm)
builder.add_edge(START, "tool_calling_llm")
builder.add_edge("tool_calling_llm", END)
graph = builder.compile()
# 可视化
display(Image(graph.get_graph().draw_mermaid_png()))
# 测试执行(普通对话)
print("=== 普通对话测试 ===")
result = graph.invoke({"messages": [HumanMessage(content="Hello!")]})
for m in result['messages']:
m.pretty_print()
# 测试执行(工具调用)
print("\n=== 工具调用测试 ===")
result = graph.invoke({"messages": [HumanMessage(content="Multiply 2 and 3")]})
for m in result['messages']:
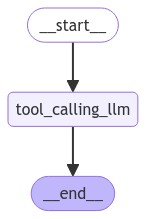
m.pretty_print()生成的流程图:
代码详解
1. 定义节点函数
def tool_calling_llm(state: MessagesState):
# ^^^^^^^^^^^^^^^^^^^^^^
# 输入:当前图状态
result = llm_with_tools.invoke(state["messages"])
# ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
# 调用 LLM,传入对话历史
return {"messages": [result]}
# ^^^^^^^^^^^^^^^^^^^^^^^
# 返回新消息(会被 add_messages 追加)2. 创建图
builder = StateGraph(MessagesState)
# ^^^^^^^^^^^^^^
# 指定状态类型3. 添加节点
builder.add_node("tool_calling_llm", tool_calling_llm)
# ^^^^^^^^^^^^^^^^^^ ^^^^^^^^^^^^^^^^^
# 节点名称 节点函数4. 添加边
builder.add_edge(START, "tool_calling_llm")
# ^^^^^ ^^^^^^^^^^^^^^^^^^
# 起点 目标节点
builder.add_edge("tool_calling_llm", END)
# ^^^^^^^^^^^^^^^^^^ ^^^
# 源节点 终点LangGraph 知识点:START 和 END
START:特殊节点,表示图的入口END:特殊节点,表示图的出口- 不是字符串,而是常量标识符
5. 编译图
graph = builder.compile()编译后的图可以执行(invoke、stream 等)。
图的可视化
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))输出:
┌─────────┐
│ __start__ │
└─────┬─────┘
│
↓
┌─────────────────┐
│ tool_calling_llm │
└─────────┬─────────┘
│
↓
┌─────────┐
│ __end__ │
└─────────┘8. 执行图
场景 1:普通对话
messages = graph.invoke({"messages": HumanMessage(content="Hello!")})
for m in messages['messages']:
m.pretty_print()输出:
================================ Human Message =================================
Hello!
================================== Ai Message ==================================
Hi there! How can I assist you today?分析:
- 输入不需要工具,LLM 直接回复
- 没有工具调用信息
场景 2:工具调用
messages = graph.invoke({"messages": HumanMessage(content="Multiply 2 and 3")})
for m in messages['messages']:
m.pretty_print()输出:
================================ Human Message =================================
Multiply 2 and 3
================================== Ai Message ==================================
Tool Calls:
multiply (call_Er4gChFoSGzU7lsuaGzfSGTQ)
Call ID: call_Er4gChFoSGzU7lsuaGzfSGTQ
Args:
a: 2
b: 3分析:
- LLM 识别出需要使用
multiply工具 - 返回工具调用信息,但 尚未执行
- 参数
a=2, b=3从自然语言中提取
🎓 核心知识点总结
LangGraph/LangChain 特有概念
1. 消息系统
| 消息类型 | 用途 | 示例 |
|---|---|---|
HumanMessage | 用户输入 | HumanMessage(content="Hi") |
AIMessage | 模型输出 | AIMessage(content="Hello!") |
SystemMessage | 系统指令 | SystemMessage(content="You are helpful") |
ToolMessage | 工具结果 | ToolMessage(content="6", tool_call_id="...") |
2. 工具绑定
# 定义工具(普通 Python 函数)
def multiply(a: int, b: int) -> int:
"""Multiply two numbers"""
return a * b
# 绑定到模型
llm_with_tools = llm.bind_tools([multiply])关键点:
- 函数签名 → 自动生成工具 schema
- 文档字符串 → 帮助模型理解用途
- 类型注解 → 定义参数和返回值类型
3. Reducers
作用: 控制状态更新方式
# 默认行为:覆盖
messages: list[AnyMessage]
# 使用 reducer:追加
messages: Annotated[list[AnyMessage], add_messages]常用 reducers:
add_messages:追加消息(去重)operator.add:列表拼接- 自定义函数:完全控制更新逻辑
4. 图的构建模式
# 1. 创建图
builder = StateGraph(StateClass)
# 2. 添加节点
builder.add_node("node_name", node_function)
# 3. 添加边
builder.add_edge(START, "node_name")
builder.add_edge("node_name", END)
# 4. 编译
graph = builder.compile()
# 5. 执行
result = graph.invoke(initial_state)Python 特有知识点
1. TypedDict
作用: 定义字典的结构和类型
from typing_extensions import TypedDict
class MyState(TypedDict):
name: str
age: int
# 使用
state: MyState = {"name": "Alice", "age": 30}特点:
- 仅用于类型检查(静态分析)
- 运行时仍是普通字典
- 提供 IDE 自动补全
2. Type Hints(类型注解)
def greet(name: str) -> str:
# ^^^^^ ^^^^^
# 参数类型 返回值类型
return f"Hello, {name}"用途:
- 文档化代码
- IDE 支持
- 静态类型检查(mypy)
- LangChain 工具 schema 生成
3. Annotated
作用: 为类型添加元数据
from typing import Annotated
# 基础类型 + 元数据
Age = Annotated[int, "Must be positive"]
# 在 LangGraph 中
messages: Annotated[list, add_messages]
# ^^^^ ^^^^^^^^^^^^^
# 类型 元数据(reducer)LangGraph 使用场景:
class State(TypedDict):
# 会被覆盖
count: int
# 会被累加
scores: Annotated[list[int], operator.add]
# 会被追加(去重)
messages: Annotated[list[AnyMessage], add_messages]4. 环境变量
import os
# 设置
os.environ["KEY"] = "value"
# 获取
value = os.environ.get("KEY")
# 安全输入
import getpass
api_key = getpass.getpass("API Key: ")💡 最佳实践
1. 消息管理
✅ 好的做法
# 明确指定消息角色和名称
messages = [
SystemMessage(content="You are a helpful assistant"),
HumanMessage(content="What's the weather?", name="User"),
AIMessage(content="I'll check that for you", name="Assistant")
]❌ 避免的做法
# 不要混用字符串和消息对象
messages = ["Hello", HumanMessage(content="Hi")] # 错误!2. 工具定义
✅ 好的做法
def calculate_discount(price: float, discount_percent: float) -> float:
"""Calculate the discounted price.
Args:
price: Original price in dollars
discount_percent: Discount percentage (0-100)
Returns:
Final price after discount
"""
return price * (1 - discount_percent / 100)特点:
- 完整的类型注解
- 详细的文档字符串
- 清晰的参数说明
❌ 避免的做法
def calc(p, d): # 无类型注解,无文档
return p * (1 - d / 100)3. 状态设计
✅ 好的做法
class ChatState(MessagesState):
user_id: str
session_started_at: str
# messages 自动继承,带 add_messages reducer❌ 避免的做法
# 不要手动管理消息列表
class ChatState(TypedDict):
all_messages: list # 无类型,无 reducer4. 节点函数
✅ 好的做法
def process_message(state: MessagesState) -> dict:
"""Process user message and generate response."""
try:
response = llm.invoke(state["messages"])
return {"messages": [response]}
except Exception as e:
logger.error(f"LLM error: {e}")
return {"messages": [AIMessage(content="Sorry, an error occurred")]}特点:
- 明确的类型注解
- 错误处理
- 返回正确的状态格式
❌ 避免的做法
def process(s): # 无类型,无错误处理
return llm.invoke(s["messages"]) # 返回格式错误🚀 进阶技巧
1. 自定义 Reducer
除了 add_messages,你可以定义自定义 reducer:
def keep_last_n_messages(existing: list, new: list, n: int = 10) -> list:
"""只保留最近 N 条消息"""
combined = existing + new
return combined[-n:]
class State(TypedDict):
messages: Annotated[list, lambda x, y: keep_last_n_messages(x, y, 5)]2. 条件工具调用
def smart_node(state: MessagesState):
response = llm_with_tools.invoke(state["messages"])
if response.tool_calls:
# 有工具调用 → 执行工具
tool_name = response.tool_calls[0]["name"]
tool_args = response.tool_calls[0]["args"]
if tool_name == "multiply":
result = multiply(**tool_args)
return {"messages": [
response,
ToolMessage(content=str(result), tool_call_id=response.tool_calls[0]["id"])
]}
# 无工具调用 → 直接返回
return {"messages": [response]}3. 多模型支持
class ModelState(MessagesState):
current_model: str
def adaptive_node(state: ModelState):
# 根据状态选择不同模型
if state["current_model"] == "fast":
llm = ChatOpenAI(model="gpt-3.5-turbo")
else:
llm = ChatOpenAI(model="gpt-5-nano")
response = llm.invoke(state["messages"])
return {"messages": [response]}🔍 常见问题
Q1: 为什么需要 add_messages reducer?
答: 因为对话需要保留历史记录。
# 没有 reducer(错误)
state = {"messages": [msg1, msg2]}
node_output = {"messages": [msg3]}
# 结果:msg1, msg2 丢失!
# 有 add_messages(正确)
state = {"messages": [msg1, msg2]}
node_output = {"messages": [msg3]}
# 结果:[msg1, msg2, msg3] ← 保留历史Q2: invoke() 和 stream() 有什么区别?
# invoke:等待全部完成,返回最终结果
result = graph.invoke({"messages": [HumanMessage(content="Hi")]})
# stream:流式返回中间结果
for chunk in graph.stream({"messages": [HumanMessage(content="Hi")]}):
print(chunk)使用场景:
invoke:需要完整结果时stream:需要实时反馈时(如聊天界面)
Q3: 工具调用后如何执行工具?
本教程中,LLM 只返回工具调用信息,不执行。完整的工具执行流程需要:
- 检测
response.tool_calls - 调用实际函数
- 将结果作为
ToolMessage返回 - 再次调用 LLM 生成最终回答
这将在后续教程中详细介绍。
Q4: TypedDict 和 Pydantic BaseModel 如何选择?
| 场景 | 使用 |
|---|---|
| 定义图状态 | TypedDict |
| LLM 结构化输出 | BaseModel |
| API 请求/响应 | BaseModel |
| 需要数据验证 | BaseModel |
| 仅需类型提示 | TypedDict |
# 图状态
class State(TypedDict):
messages: list
# 工具输出
class ToolOutput(BaseModel):
result: int
status: str📊 概念对比
Chain vs Graph
| 特性 | Chain | Graph |
|---|---|---|
| 结构 | 线性(A→B→C) | 任意(可循环、分支) |
| 复杂度 | 简单 | 复杂 |
| 适用场景 | 简单流程 | 复杂工作流 |
| 本教程 | ✅ | ✅(简单图) |
本教程使用了简单的线性图(chain),但使用了 StateGraph 构建,为后续复杂图打基础。
Messages vs State
# 仅消息
def node1(messages: list[AnyMessage]) -> list[AnyMessage]:
return llm.invoke(messages)
# 使用状态(推荐)
def node2(state: MessagesState) -> dict:
return {"messages": [llm.invoke(state["messages"])]}使用状态的优势:
- 可以添加额外信息(user_id、metadata 等)
- 统一的更新机制(reducers)
- 更好的扩展性
🎯 实际应用案例
案例 1:简单客服机器人
from langgraph.graph import StateGraph, MessagesState, START, END
# 工具:查询订单
def check_order(order_id: str) -> str:
"""Check order status"""
return f"Order {order_id} is being processed"
# 节点
def customer_service(state: MessagesState):
llm_with_tools = ChatOpenAI(model="gpt-5-nano").bind_tools([check_order])
response = llm_with_tools.invoke(state["messages"])
return {"messages": [response]}
# 构建图
builder = StateGraph(MessagesState)
builder.add_node("service", customer_service)
builder.add_edge(START, "service")
builder.add_edge("service", END)
app = builder.compile()
# 使用
result = app.invoke({"messages": [HumanMessage(content="Check order #12345")]})案例 2:多语言翻译助手
def translate(text: str, target_language: str) -> str:
"""Translate text to target language"""
# 实际调用翻译 API
return f"[{target_language}] {text}"
def translator_bot(state: MessagesState):
llm_with_tools = ChatOpenAI(model="gpt-5-nano").bind_tools([translate])
response = llm_with_tools.invoke(state["messages"])
return {"messages": [response]}
# 使用
result = app.invoke({
"messages": [HumanMessage(content="Translate 'Hello' to Spanish")]
})📖 下一步学习
本教程介绍了 Chain 的基础概念,下一步你将学习:
- Tool Execution(工具执行):实际执行工具调用并返回结果
- Conditional Edges(条件边):根据状态动态路由
- Cycles(循环):构建可以多轮交互的图
- Memory(记忆):持久化对话历史
🔗 扩展阅读
- LangChain Messages 文档
- LangChain Chat Models 文档
- LangChain Tools 文档
- LangGraph Reducers 文档
- Python Type Hints 指南
总结:本教程介绍了构建 LangGraph Chain 的四大核心概念:消息系统、聊天模型、工具绑定和状态管理。这些是构建复杂 AI 系统的基础,掌握这些概念后,你就可以开始构建更强大的 LangGraph 应用了!