Middleware 中间件:给你的 AI Agent 装上"安检门"
在构建 AI Agent 时,你是否遇到过这些问题?
- 想在 Agent 调用 LLM 之前检查一下输入是否合规
- 想在 Agent 执行工具之前让人工确认一下
- 想自动压缩过长的对话历史,避免超出 Token 限制
- 想记录 Agent 的每一步操作,方便调试
Middleware(中间件) 就是为解决这些问题而生的。
什么是中间件?一个生活中的比喻
想象你要进入一栋大楼:
你 → [安检门] → [前台登记] → [访客证发放] → 进入大楼在这个过程中,安检门、前台登记、访客证发放都是"中间件"——它们:
- 不改变你的最终目的(进入大楼)
- 在你到达目的地之前/之后执行额外的操作
- 可以灵活增减(VIP 可能跳过安检,普通访客需要全部流程)
在 AI Agent 中,中间件的作用类似:
用户请求 → [日志记录] → [权限检查] → [内容审核] → LLM 处理 → [结果过滤] → 返回用户每个方括号里的步骤都是一个中间件,它们可以:
- 拦截:阻止不合规的请求
- 修改:调整请求或响应的内容
- 记录:保存执行过程供分析
- 增强:添加额外的处理逻辑
LangGraph 1.0 中的 Middleware
LangChain/LangGraph 1.0 版本引入了全新的 Agent Middleware 抽象,让你能够在 Agent 执行的每一步插入自定义逻辑。

中间件在 Agent 循环中的位置
一个标准的 Agent 循环是这样的:
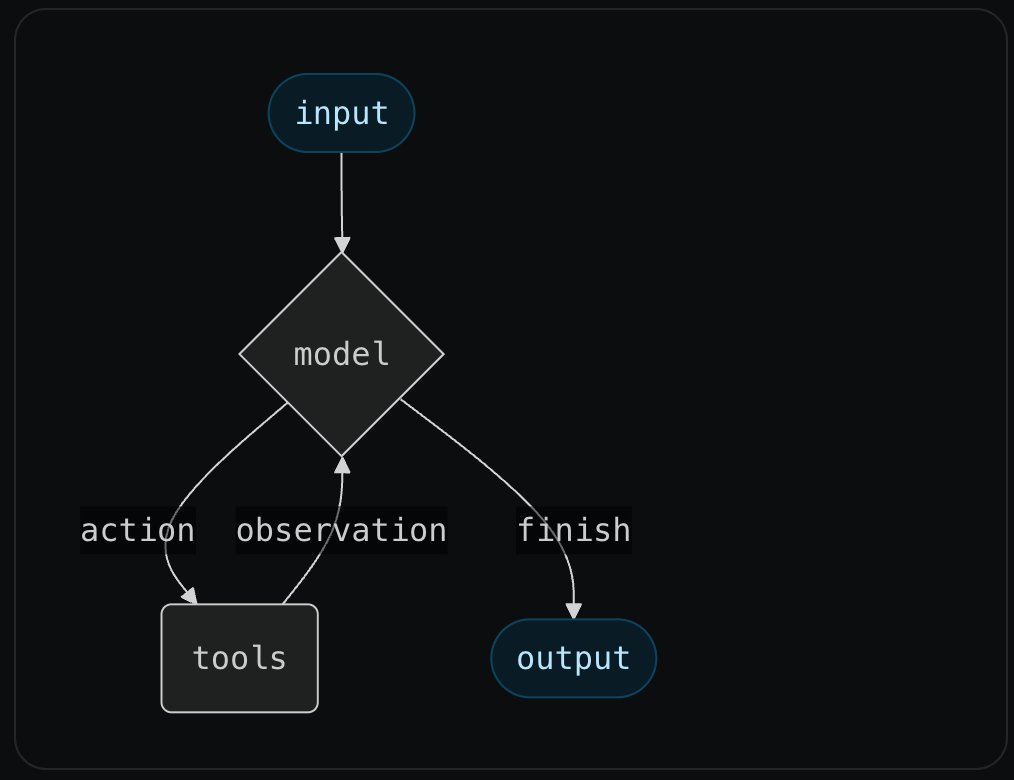
START → 调用 LLM → 判断是否需要工具 → 执行工具 → 返回 LLM → ... → END中间件可以在这个循环的多个关键点插入:
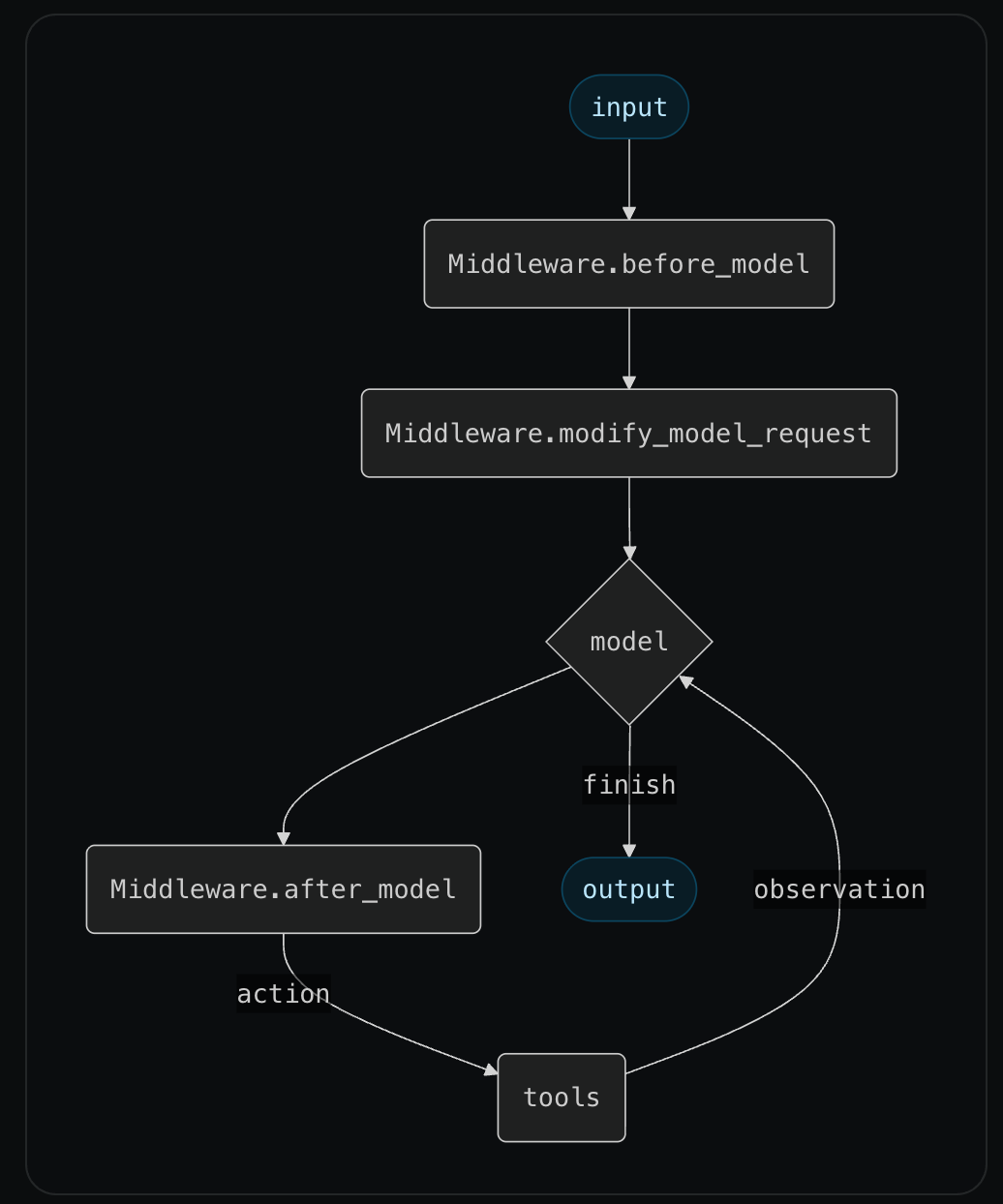
三大核心钩子
LangGraph Middleware 提供了三个核心钩子函数:
1. before_model - 模型调用前
在 LLM 被调用之前执行,可以:
- 检查和修改输入状态
- 决定是否跳过模型调用
- 直接跳转到其他节点
def before_model(state, config):
"""在模型调用前执行"""
# 检查是否有敏感词
if contains_sensitive_words(state["messages"]):
# 可以选择跳过模型调用,直接返回预设回复
return Command(goto=END, update={
"messages": [AIMessage("抱歉,我无法处理这类请求")]
})
# 正常继续执行
return state使用场景:
- 内容审核
- 权限验证
- 请求预处理
2. after_model - 模型调用后
在 LLM 返回结果后执行,可以:
- 审核模型的输出
- 实现人工确认机制
- 添加保护机制
def after_model(state, config):
"""在模型调用后执行"""
last_message = state["messages"][-1]
# 检查模型是否要执行危险操作
if has_dangerous_tool_call(last_message):
# 暂停执行,等待人工确认
human_approved = interrupt({
"question": "模型想要执行敏感操作,是否批准?",
"action": last_message.tool_calls
})
if not human_approved:
return Command(goto=END, update={
"messages": [AIMessage("操作已被用户取消")]
})
return state使用场景:
- Human-in-the-loop(人工审核)
- 输出过滤
- 结果增强
3. modify_model_request - 修改模型请求
在发送给 LLM 之前,修改请求的各个方面:
- 工具列表
- 提示词
- 消息历史
- 模型参数
- 输出格式
def modify_model_request(state, config, request):
"""修改发送给模型的请求"""
# 根据用户权限动态调整可用工具
user_role = config.get("user_role", "guest")
if user_role == "admin":
# 管理员可以使用所有工具
pass
else:
# 普通用户只能使用安全工具
request.tools = [t for t in request.tools if t.name in SAFE_TOOLS]
# 压缩过长的消息历史
if len(request.messages) > 50:
request.messages = summarize_messages(request.messages)
return request使用场景:
- 动态工具选择
- 消息历史压缩
- 提示词注入
- 模型参数调整
中间件执行顺序
中间件按照洋葱模型执行:
请求进入 → middleware_1 → middleware_2 → middleware_3 → LLM
↓
响应返回 ← middleware_1 ← middleware_2 ← middleware_3 ← LLM- 进入时:按添加顺序执行(1 → 2 → 3)
- 返回时:按相反顺序执行(3 → 2 → 1)
这和 Web 服务器的中间件模式完全一致。
内置中间件大全
LangChain/LangGraph 1.0 提供了丰富的内置中间件,分为通用中间件和特定厂商中间件两类。
一、通用中间件(Provider-Agnostic)
这些中间件可以与任何 LLM 厂商配合使用。
1. Human-in-the-Loop(人工审核)
让用户可以批准、编辑或拒绝 Agent 的工具调用。需要配合 Checkpointer 使用以维护中断状态。
from langchain.middleware import HumanApprovalMiddleware
middleware = HumanApprovalMiddleware(
# 只对特定工具要求人工审核
tools_requiring_approval=["send_email", "delete_file", "transfer_money"]
)
agent = create_react_agent(
model=llm,
tools=tools,
middleware=[middleware],
checkpointer=checkpointer # 必须配置 checkpointer
)适用场景:涉及外部系统的操作、金融交易、数据删除、发送通知
2. Summarization(消息摘要)
当消息历史接近上下文限制时,自动压缩早期对话,保留最近的消息原文。
from langchain.middleware import SummarizationMiddleware
middleware = SummarizationMiddleware(
model="gpt-4o-mini", # 用于生成摘要的模型
trigger={
"tokens": 4000, # Token 数触发
# "messages": 50, # 或按消息数触发
# "fraction": 0.8 # 或按上下文比例触发
},
keep={
"recent": 10, # 保留最近 10 条原始消息
"system": True # 保留系统消息
}
)
agent = create_react_agent(
model=llm,
tools=tools,
middleware=[middleware]
)适用场景:长对话场景、复杂任务执行、防止 Token 溢出
3. PII Detection(隐私信息检测)
自动识别和处理敏感信息,支持多种处理策略。
from langchain.middleware import PIIDetectionMiddleware
middleware = PIIDetectionMiddleware(
# 内置检测器
detectors=["email", "credit_card", "phone", "ip_address"],
# 自定义检测器(正则表达式)
custom_patterns={
"chinese_id": r'\b\d{17}[\dXx]\b',
"chinese_phone": r'\b1[3-9]\d{9}\b'
},
# 处理策略:redact(删除)、mask(掩码)、hash(哈希)、block(阻止)
strategy="mask"
)
agent = create_react_agent(
model=llm,
tools=tools,
middleware=[middleware]
)适用场景:客服系统、医疗健康应用、金融服务、GDPR/隐私合规
4. Model Call Limit(模型调用限制)
限制单次运行或单个会话中的模型调用次数,防止无限循环。
from langchain.middleware import ModelCallLimitMiddleware
middleware = ModelCallLimitMiddleware(
run_limit=10, # 单次运行最多调用 10 次
thread_limit=100 # 单个会话累计最多 100 次
)适用场景:成本控制、防止死循环、资源保护
5. Tool Call Limit(工具调用限制)
控制工具的执行次数,支持全局限制和单工具限制。
from langchain.middleware import ToolCallLimitMiddleware
middleware = ToolCallLimitMiddleware(
thread_limit=20, # 单会话总工具调用上限
run_limit=5, # 单次运行工具调用上限
per_tool_limits={ # 单工具调用上限
"web_search": 3,
"file_write": 1
},
# 达到限制后的行为:continue(继续但阻止调用)、error(抛异常)、end(结束)
on_limit="continue"
)适用场景:API 配额管理、防止滥用、成本控制
6. Model Fallback(模型降级)
当主模型失败时,自动切换到备用模型。
from langchain.middleware import ModelFallbackMiddleware
middleware = ModelFallbackMiddleware(
fallback_models=["gpt-4o-mini", "claude-3-5-sonnet"], # 按顺序尝试
retry_on_errors=[RateLimitError, APIError] # 触发降级的错误类型
)
agent = create_react_agent(
model="gpt-4o", # 主模型
tools=tools,
middleware=[middleware]
)适用场景:高可用系统、成本优化(昂贵模型失败时降级到便宜模型)
7. Retry Middleware(重试机制)
为模型调用和工具调用添加自动重试,支持指数退避。
from langchain.middleware import ModelRetryMiddleware, ToolRetryMiddleware
# 模型重试
model_retry = ModelRetryMiddleware(
max_retries=3,
initial_delay=1.0, # 初始延迟秒数
exponential_base=2, # 指数退避基数
jitter=True # 添加随机抖动
)
# 工具重试
tool_retry = ToolRetryMiddleware(
max_retries=2,
retry_on_errors=[TimeoutError, ConnectionError]
)适用场景:网络不稳定环境、API 限流处理、提高系统鲁棒性
8. LLM Tool Selector(智能工具选择)
当 Agent 拥有大量工具时,先用小模型筛选相关工具,再调用主模型,减少 Token 消耗。
from langchain.middleware import LLMToolSelectorMiddleware
middleware = LLMToolSelectorMiddleware(
selector_model="gpt-4o-mini", # 用小模型做初筛
max_tools=5 # 最多选择 5 个工具给主模型
)
# 假设有 50 个工具,中间件会先筛选出最相关的 5 个
agent = create_react_agent(
model="gpt-4o",
tools=all_50_tools,
middleware=[middleware]
)适用场景:工具数量多的 Agent、降低 Token 成本、提高工具选择准确性
9. To-Do List(任务规划)
自动为 Agent 添加任务规划能力,提供 write_todos 工具和相关系统提示。
from langchain.middleware import TodoListMiddleware
middleware = TodoListMiddleware(
auto_create=True, # 自动创建任务列表
track_progress=True # 追踪任务完成进度
)适用场景:复杂多步骤任务、项目管理类 Agent
10. LLM Tool Emulator(工具模拟器)
用 LLM 生成模拟的工具响应,而不是真正执行工具,适合测试和原型开发。
from langchain.middleware import LLMToolEmulatorMiddleware
middleware = LLMToolEmulatorMiddleware(
emulator_model="gpt-4o-mini",
tools_to_emulate=["database_query", "api_call"] # 要模拟的工具
)适用场景:Agent 原型开发、测试环境、演示 Demo
11. Context Editing(上下文编辑)
管理上下文窗口,清理早期的工具调用输出,保留最近的结果。
from langchain.middleware import ClearToolUsesMiddleware
middleware = ClearToolUsesMiddleware(
keep_recent=5, # 保留最近 5 次工具调用的输出
clear_errors=True # 清理错误的工具调用
)适用场景:上下文管理、减少 Token 使用
12. Shell Tool(Shell 命令执行)
为 Agent 提供持久化的 Shell 会话,支持多种执行环境。
from langchain.middleware import ShellToolMiddleware
middleware = ShellToolMiddleware(
# 执行策略:host(本机)、docker(容器)、codex_sandbox(沙箱)
execution_policy="docker",
allowed_commands=["ls", "cat", "grep", "python"] # 白名单
)适用场景:代码执行 Agent、系统管理 Agent、DevOps 自动化
13. File Search(文件搜索)
为 Agent 提供 glob 和 grep 搜索能力。
from langchain.middleware import FilesystemFileSearchMiddleware
middleware = FilesystemFileSearchMiddleware(
root_path="/workspace",
allowed_extensions=[".py", ".md", ".txt"]
)适用场景:代码库探索、文档检索、日志分析
二、特定厂商中间件(Provider-Specific)
这些中间件针对特定 LLM 厂商优化。
Anthropic 专用中间件
1. Prompt Caching(提示缓存)
缓存静态内容(系统提示、工具定义),减少成本和延迟。
from langchain.middleware import AnthropicPromptCachingMiddleware
middleware = AnthropicPromptCachingMiddleware(
cache_system_prompt=True,
cache_tools=True
)优势:可节省 50-90% 的输入 Token 成本
2. Claude Bash Tool(Bash 工具封装)
将 Shell 执行封装为 Claude 的原生 bash 工具格式。
from langchain.middleware import ClaudeBashToolMiddleware
middleware = ClaudeBashToolMiddleware(
timeout=30,
working_dir="/workspace"
)3. Claude Text Editor(文本编辑器)
支持 Claude 的 text_editor 工具,用于文件创建和编辑。
from langchain.middleware import FilesystemClaudeTextEditorMiddleware
middleware = FilesystemClaudeTextEditorMiddleware(
root_path="/workspace",
allowed_extensions=[".py", ".js", ".md"]
)4. Claude Memory(持久记忆)
为 Claude Agent 提供跨对话的持久记忆。
from langchain.middleware import FilesystemClaudeMemoryMiddleware
middleware = FilesystemClaudeMemoryMiddleware(
memory_path="./agent_memory"
)OpenAI 专用中间件
OpenAI Moderation(内容审核)
使用 OpenAI 的内容审核 API 检测不安全内容。
from langchain.middleware import OpenAIModerationMiddleware
middleware = OpenAIModerationMiddleware(
check_input=True, # 检查用户输入
check_output=True, # 检查模型输出
check_tool_results=True,# 检查工具返回
on_violation="block" # 违规时阻止(或 "warn")
)检测类别:仇恨言论、骚扰、自残、性内容、暴力等
自定义中间件
除了内置中间件,你可以轻松创建自己的中间件:
from langchain.middleware import BaseMiddleware
class LoggingMiddleware(BaseMiddleware):
"""记录 Agent 每一步操作的中间件"""
def before_model(self, state, config):
print(f"[LOG] 即将调用 LLM,当前消息数: {len(state['messages'])}")
return state
def after_model(self, state, config):
last_msg = state["messages"][-1]
if hasattr(last_msg, 'tool_calls') and last_msg.tool_calls:
print(f"[LOG] LLM 决定调用工具: {[tc['name'] for tc in last_msg.tool_calls]}")
else:
print(f"[LOG] LLM 生成了最终回复")
return state
class CostTrackingMiddleware(BaseMiddleware):
"""追踪 Token 消耗的中间件"""
def __init__(self):
self.total_tokens = 0
def after_model(self, state, config):
# 从响应中提取 Token 使用量
last_msg = state["messages"][-1]
if hasattr(last_msg, 'response_metadata'):
usage = last_msg.response_metadata.get('token_usage', {})
self.total_tokens += usage.get('total_tokens', 0)
print(f"[COST] 本次消耗: {usage.get('total_tokens', 0)} tokens")
print(f"[COST] 累计消耗: {self.total_tokens} tokens")
return state
# 使用自定义中间件
agent = create_react_agent(
model=llm,
tools=tools,
middleware=[
LoggingMiddleware(),
CostTrackingMiddleware(),
HumanApprovalMiddleware(tools_requiring_approval=["send_email"])
]
)完整示例:构建一个安全的客服 Agent
下面是一个综合示例,展示如何使用多个中间件构建一个安全、可控的客服 Agent:
from langchain_openai import ChatOpenAI
from langchain.agents import create_react_agent
from langchain.middleware import (
HumanApprovalMiddleware,
SummarizationMiddleware,
PIIRedactionMiddleware
)
# 定义工具
tools = [
query_order_status, # 查询订单状态
update_shipping_address, # 修改收货地址(需要确认)
process_refund, # 处理退款(需要确认)
send_notification # 发送通知(需要确认)
]
# 配置中间件
middlewares = [
# 1. 隐私信息脱敏
PIIRedactionMiddleware(
patterns=[
r'\b1[3-9]\d{9}\b', # 手机号
r'\b\d{17}[\dXx]\b', # 身份证
]
),
# 2. 消息摘要(长对话自动压缩)
SummarizationMiddleware(
max_messages=50,
preserve_recent=5
),
# 3. 敏感操作需人工确认
HumanApprovalMiddleware(
tools_requiring_approval=[
"update_shipping_address",
"process_refund",
"send_notification"
]
)
]
# 创建 Agent
llm = ChatOpenAI(model="gpt-4o", temperature=0)
agent = create_react_agent(
model=llm,
tools=tools,
middleware=middlewares,
prompt="你是一个专业的电商客服助手..."
)
# 运行
result = agent.invoke({
"messages": [{"role": "user", "content": "我想修改订单 12345 的收货地址"}]
})中间件 vs 其他方案
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 中间件 | 解耦、可复用、易测试 | 需要学习新概念 | 通用的横切关注点 |
| 直接修改节点 | 简单直接 | 代码耦合度高 | 一次性的特殊逻辑 |
| 条件边 | 灵活控制流程 | 图结构变复杂 | 流程分支决策 |
| Subgraph | 模块化封装 | 状态传递麻烦 | 复杂子流程 |
最佳实践
1. 中间件职责单一
每个中间件只做一件事:
# 好的做法:职责单一
LoggingMiddleware() # 只负责日志
CostMiddleware() # 只负责成本追踪
PIIMiddleware() # 只负责脱敏
# 不好的做法:职责混乱
class DoEverythingMiddleware: # 一个中间件做所有事情
def before_model(self, state, config):
self.log_input()
self.check_pii()
self.validate_permission()
self.track_cost()
...2. 注意执行顺序
中间件的顺序很重要:
# 推荐顺序
middlewares = [
PIIRedactionMiddleware(), # 1. 先脱敏
LoggingMiddleware(), # 2. 再记录(记录的是脱敏后的数据)
SummarizationMiddleware(), # 3. 然后压缩
HumanApprovalMiddleware() # 4. 最后人工确认
]3. 错误处理
中间件中的错误应该优雅处理:
class SafeMiddleware(BaseMiddleware):
def before_model(self, state, config):
try:
# 你的逻辑
pass
except Exception as e:
# 记录错误但不影响主流程
logger.error(f"Middleware error: {e}")
return state # 确保总是返回 state总结
Middleware 是 LangGraph 1.0 中一个强大的抽象,它让你能够:
| 功能 | 钩子 | 典型用途 |
|---|---|---|
| 预处理 | before_model | 内容审核、权限检查、输入验证 |
| 后处理 | after_model | 人工审核、输出过滤、结果增强 |
| 请求修改 | modify_model_request | 动态工具、消息压缩、提示注入 |
通过合理使用中间件,你可以构建出安全、可控、可观测的 AI Agent 系统。