Deep Agents 深度智能体
深度智能体(Deep Agents)是一个用于构建生产级智能体的库,基于 LangGraph 构建。
概述
deepagents 是一个高级智能体框架,基于 LangGraph 构建。它汲取了 Claude Code 和 Deep Research 等产品的经验,提供了构建可靠生产级智能体的最佳实践。
为什么选择 Deep Agents
Deep Agents 提供以下核心功能:
- 任务管理系统:内置待办事项追踪
- 文件系统操作:完整的文件读写能力
- 子智能体架构:支持嵌套和委托
- 长期记忆:跨会话的持久化存储
这些功能组合比单独使用 LangChain 的 create_agent 或 LangGraph 更加强大。
架构总览
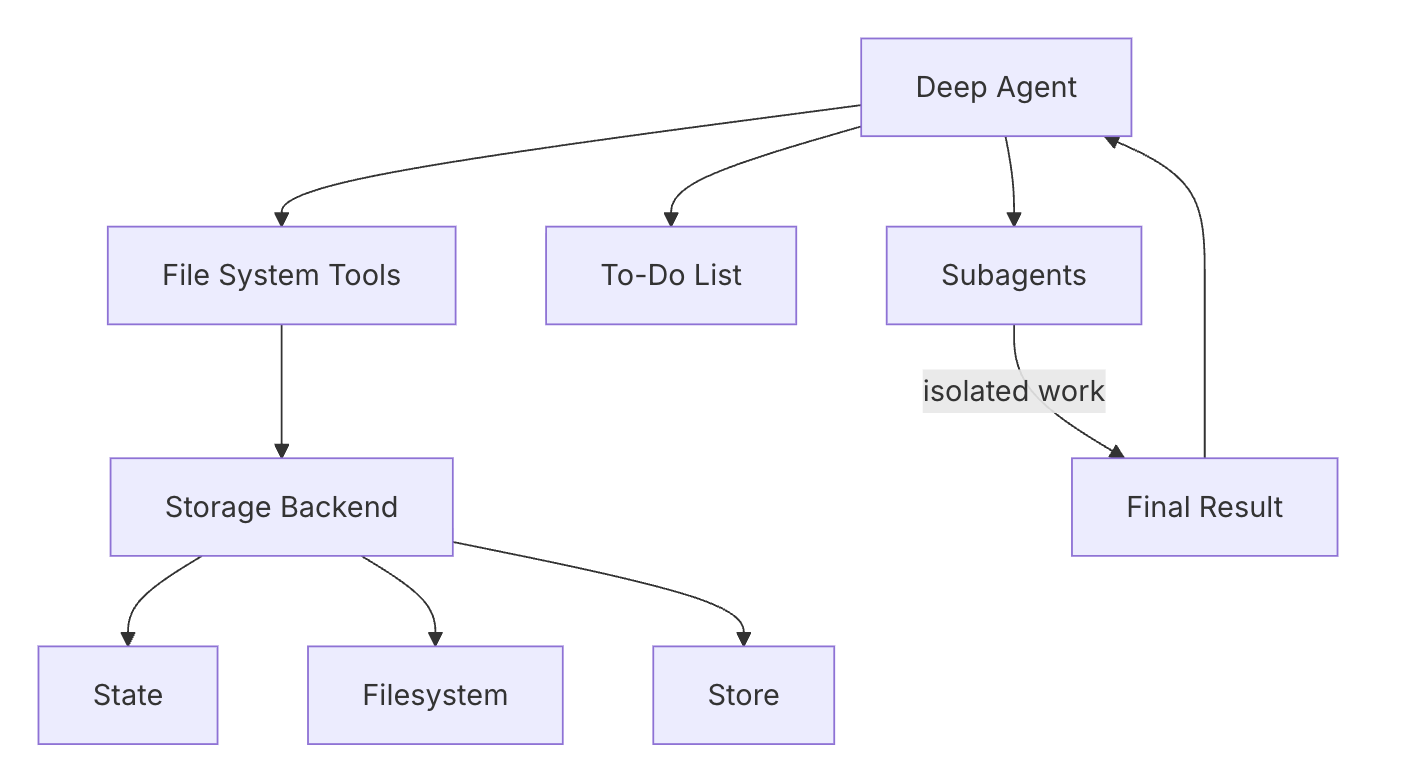
graph TD
A[Deep Agent] --> B[任务管理]
A --> C[文件系统]
A --> D[子智能体]
A --> E[记忆]
B --> B1[write_todos 工具]
B --> B2[状态追踪]
B --> B3[进度报告]
C --> C1[ls - 列目录]
C --> C2[read_file - 读文件]
C --> C3[write_file - 写文件]
C --> C4[edit_file - 编辑]
D --> D1[task 工具]
D --> D2[上下文隔离]
D --> D3[并行执行]
E --> E1[LangGraph Store]
E --> E2[路径路由]| 组件 | 说明 | 相关工具 |
|---|---|---|
| 任务管理 | 智能体使用 write_todos 工具来规划任务、追踪进度、更新状态 | write_todos |
| 文件系统 | 一套完整的工具让智能体能够浏览文件、读取内容、创建和编辑文件 | ls, read_file, write_file, edit_file |
| 子智能体 | 通过 task 工具允许智能体创建子智能体,每个子智能体有独立的上下文和工具 | task |
| 记忆 | 使用 LangGraph Store 实现跨会话的持久化存储 | StoreBackend |
快速开始
安装
使用 pip:
pip install deepagents tavily-python使用 uv:
uv add deepagents tavily-python使用 poetry:
poetry add deepagents tavily-python设置 API Key
export ANTHROPIC_API_KEY="your-api-key"
export TAVILY_API_KEY="your-tavily-api-key"创建第一个 Deep Agent
下面是一个带网络搜索功能的研究智能体:
import os
from typing import Literal
from tavily import TavilyClient
from deepagents import create_deep_agent
# 初始化搜索客户端
tavily_client = TavilyClient(api_key=os.environ["TAVILY_API_KEY"])
# 定义搜索工具
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
):
"""Run a web search"""
return tavily_client.search(
query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)
# 定义系统提示
research_instructions = """You are an expert researcher. Your job is to conduct thorough research and then write a polished report.
You have access to an internet search tool as your primary means of gathering information.
## `internet_search`
Use this to run an internet search for a given query. You can specify the max number of results to return, the topic, and whether raw content should be included.
"""
# 创建 Deep Agent
agent = create_deep_agent(
tools=[internet_search],
system_prompt=research_instructions
)
# 运行智能体
result = agent.invoke({"messages": [{"role": "user", "content": "What is langgraph?"}]})
print(result["messages"][-1].content)Deep Agent 的执行流程
- 接收输入 - 解析用户消息和历史记录
- 规划 - 使用工具分解任务
- 文件操作 - 读写必要的文件
- 子智能体调用 - 将复杂任务委托给子智能体
- 输出 - 生成最终响应
自定义配置
配置架构
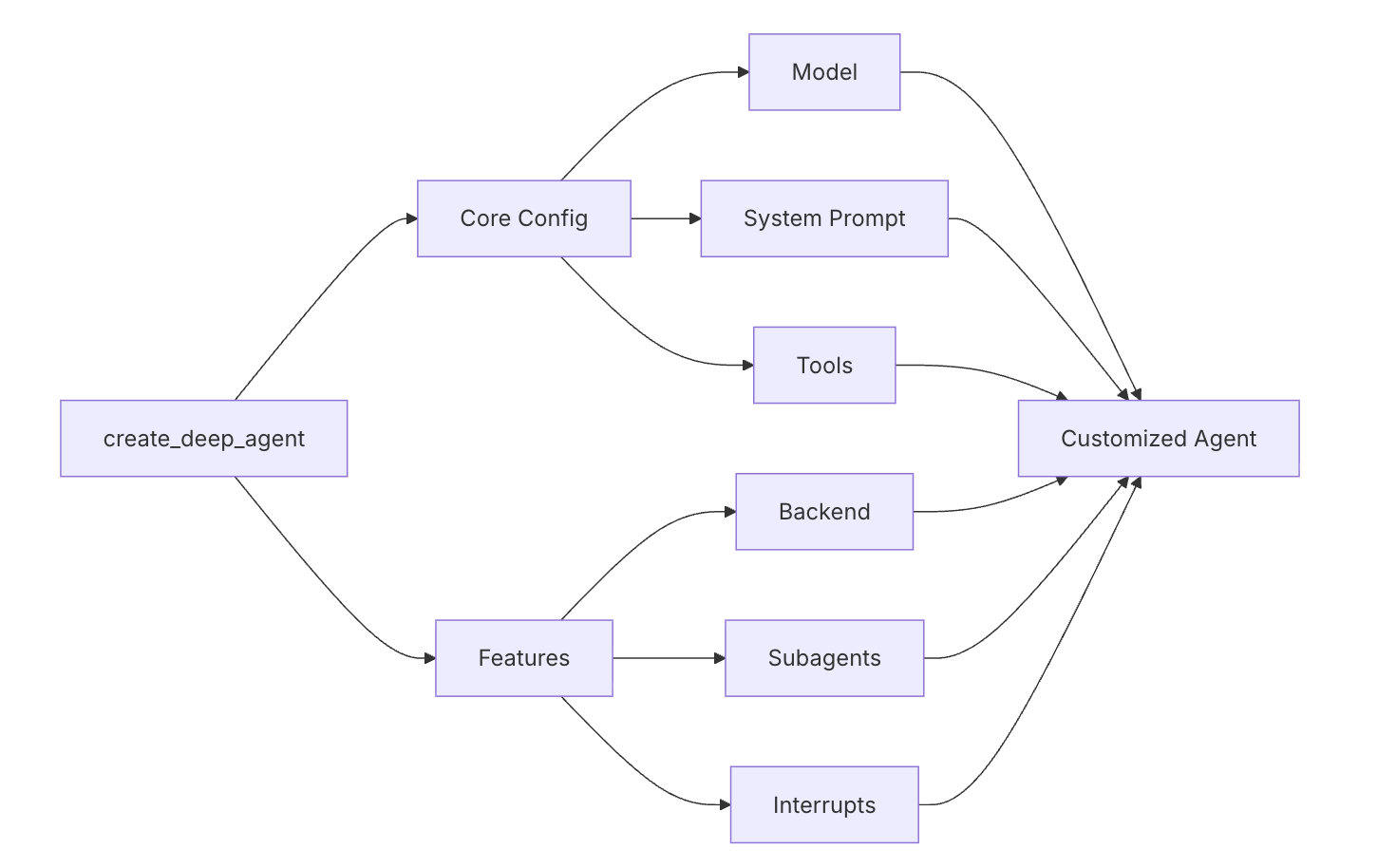
graph LR
A[create_deep_agent] --> B[Core Config]
A --> C[Features]
B --> B1[Model]
B --> B2[System Prompt]
B --> B3[Tools]
C --> C1[Backend]
C --> C2[Subagents]
C --> C3[Interrupts]
B1 --> D[Customized Agent]
B2 --> D
B3 --> D
C1 --> D
C2 --> D
C3 --> D模型配置
默认情况下,deepagents 使用 "claude-sonnet-4-5-20250929"。你也可以使用 LangChain 模型对象:
from langchain.chat_models import init_chat_model
from deepagents import create_deep_agent
model = init_chat_model(
model="gpt-4o",
)
agent = create_deep_agent(
model=model,
)系统提示
Deep Agent 类似 Claude Code,你可以提供系统提示来定义智能体的行为和个性:
from deepagents import create_deep_agent
research_instructions = """\
You are an expert researcher. Your job is to conduct \
thorough research, and then write a polished report. \
"""
agent = create_deep_agent(
system_prompt=research_instructions,
)自定义工具
智能体可以访问任意工具。默认情况下提供内置工具:
import os
from typing import Literal
from tavily import TavilyClient
from deepagents import create_deep_agent
tavily_client = TavilyClient(api_key=os.environ["TAVILY_API_KEY"])
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
):
"""Run a web search"""
return tavily_client.search(
query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)
agent = create_deep_agent(
tools=[internet_search]
)内置工具一览
| 工具 | 说明 |
|---|---|
write_todos | 管理智能体的任务待办列表 |
ls | 列出目录内容 |
read_file | 读取文件内容 |
write_file | 创建新文件 |
edit_file | 修改现有文件 |
task | 委托子智能体执行特定任务 |
Agent Harness(智能体框架)
deepagents 框架提供了智能体执行的核心架构,包含一系列常用功能:
文件系统能力
核心工具和功能:
| 工具 | 说明 |
|---|---|
ls | 列出指定路径的内容 |
read_file | 读取文件内容,支持分页 |
write_file | 创建新文件 |
edit_file | 基于字符串替换的编辑 |
glob | 按模式匹配查找文件 |
grep | 搜索文件内容 |
文件工具输出限制
所有工具输出都有最大长度限制,防止过长的输出耗尽上下文。 输出限制约为:20,000 tokens。超过此限制的内容会被截断。
上下文窗口管理
当上下文超过 170,000 tokens 时,会自动触发压缩。最近 6 条消息会被保留,较早的消息会被压缩。
工具使用限制
有多种限制机制防止工具的过度使用,避免无限循环或失控行为。
任务列表管理
write_todos 工具支持的任务状态:
pending- 待处理in_progress- 进行中completed- 已完成
安全考虑
Anthropic 实施了多层安全措施来控制智能体行为,防止滥用。
后端系统(Backends)
Deep Agent 的后端系统提供灵活的存储方案,满足不同需求。
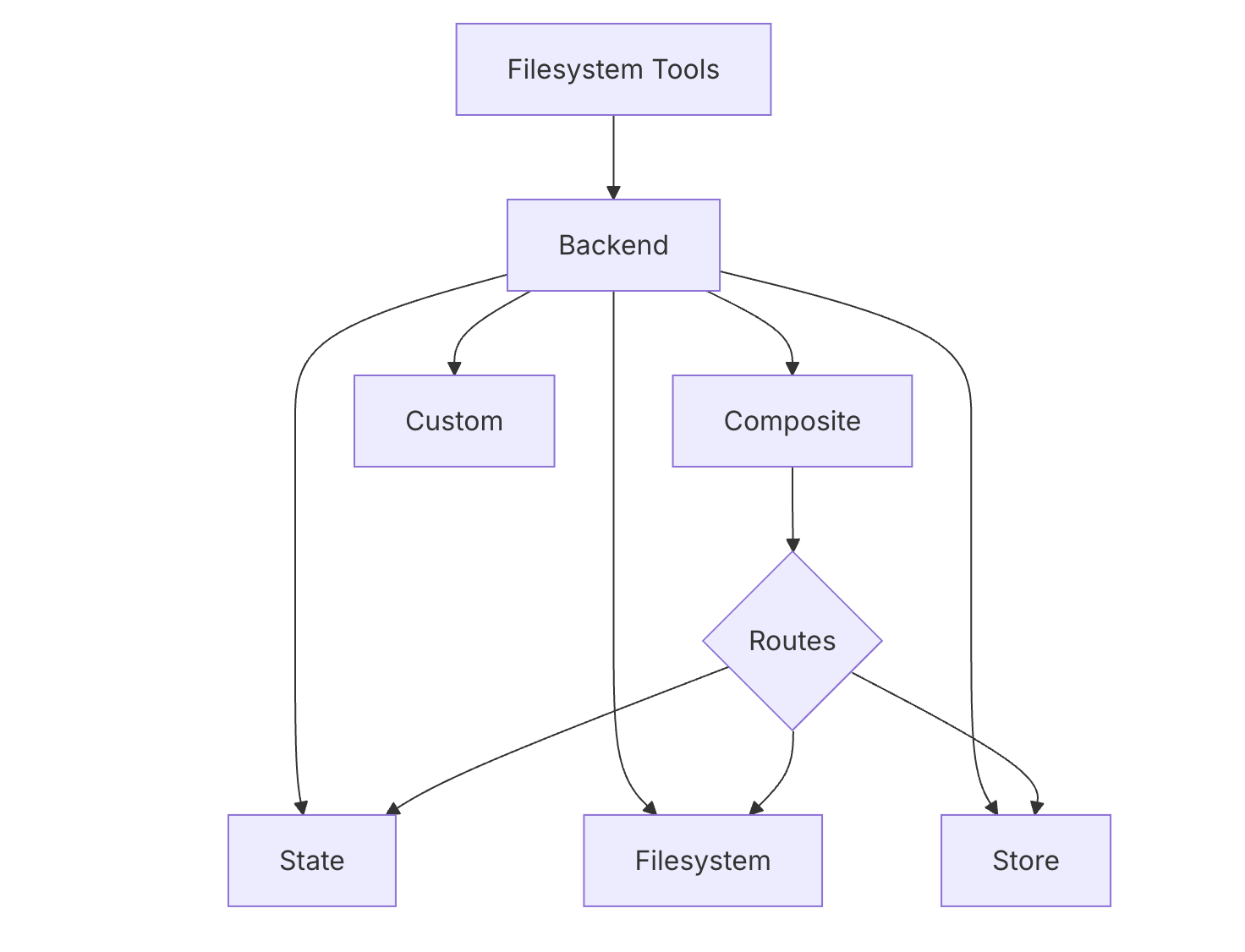
架构图
graph TD
A[Filesystem Tools] --> B[Backend Layer]
B --> C[StateBackend]
B --> D[FilesystemBackend]
B --> E[StoreBackend]
B --> F[CompositeBackend]
B --> G[Custom Backend]
F --> F1[Routes]
F1 --> C
F1 --> E后端类型对比
| 后端类型 | 说明 | 适用场景 |
|---|---|---|
| 默认 | create_deep_agent() | 临时会话,不需要持久化或跨会话存储 |
| 真实文件系统 | FilesystemBackend(root_dir="/path") | 需要真实文件操作,如代码修改 |
| 存储后端 | StoreBackend(rt) | 需要持久化的跨会话数据 |
| 组合后端 | Multiple routes | 根据路径选择不同存储 |
StateBackend(临时会话)
agent = create_deep_agent()
# 等价于
from deepagents.backends import StateBackend
agent = create_deep_agent(
backend=(lambda rt: StateBackend(rt))
)特点: 状态保存在 LangGraph 智能体的内存中,不持久化。
用途: 临时任务,无需保存历史。
FilesystemBackend(真实文件)
from deepagents.backends import FilesystemBackend
agent = create_deep_agent(
backend=FilesystemBackend(root_dir=".", virtual_mode=True)
)特点: 直接操作指定 root_dir 下的文件。virtual_mode=True 时使用虚拟环境,支持 ripgrep 等工具。
用途: 真实项目开发,代码修改等任务。
StoreBackend(LangGraph Store)
from langgraph.store.memory import InMemoryStore
from deepagents.backends import StoreBackend
agent = create_deep_agent(
backend=(lambda rt: StoreBackend(rt)),
store=InMemoryStore()
)特点: 保存到 LangGraph BaseStore 中,可持久化存储。
用途: 配置 LangGraph 持久化存储(Redis、Postgres等),或者在配置 LangSmith 时使用。
CompositeBackend(组合后端)
from deepagents import create_deep_agent
from deepagents.backends import CompositeBackend, StateBackend, StoreBackend
from langgraph.store.memory import InMemoryStore
composite_backend = lambda rt: CompositeBackend(
default=StateBackend(rt),
routes={
"/memories/": StoreBackend(rt),
}
)
agent = create_deep_agent(
backend=composite_backend,
store=InMemoryStore()
)特点: 根据路径将请求路由到不同后端。
用途: 临时文件用会话存储,持久数据用长期存储。
组合配置示例
from deepagents import create_deep_agent
from deepagents.backends import CompositeBackend, StateBackend, FilesystemBackend
composite_backend = lambda rt: CompositeBackend(
default=StateBackend(rt),
routes={
"/memories/": FilesystemBackend(root_dir="/deepagents/myagent", virtual_mode=True),
},
)
agent = create_deep_agent(backend=composite_backend)路由逻辑:
/workspace/plan.md→ StateBackend(临时)/memories/agent.md→ FilesystemBackend(持久)- 不同路径使用不同存储
- 灵活应对各种场景
自定义 S3 后端示例
from deepagents.backends.protocol import BackendProtocol, WriteResult, EditResult
from deepagents.backends.utils import FileInfo, GrepMatch
class S3Backend(BackendProtocol):
def __init__(self, bucket: str, prefix: str = ""):
self.bucket = bucket
self.prefix = prefix.rstrip("/")
def _key(self, path: str) -> str:
return f"{self.prefix}{path}"
def ls_info(self, path: str) -> list[FileInfo]:
# List objects; build FileInfo entries
...
def read(self, file_path: str, offset: int = 0, limit: int = 2000) -> str:
# Fetch object; return numbered content or error
...
def grep_raw(self, pattern: str, path: str | None = None, glob: str | None = None) -> list[GrepMatch] | str:
# Filter server-side or list and scan
...
def glob_info(self, pattern: str, path: str = "/") -> list[FileInfo]:
# Apply glob across keys
...
def write(self, file_path: str, content: str) -> WriteResult:
# Create-only semantics
return WriteResult(path=file_path, files_update=None)
def edit(self, file_path: str, old_string: str, new_string: str, replace_all: bool = False) -> EditResult:
# Read → replace → write
...高级示例 - 写保护
from deepagents.backends.filesystem import FilesystemBackend
from deepagents.backends.protocol import WriteResult, EditResult
class GuardedBackend(FilesystemBackend):
def __init__(self, *, deny_prefixes: list[str], **kwargs):
super().__init__(**kwargs)
self.deny_prefixes = [p if p.endswith("/") else p + "/" for p in deny_prefixes]
def write(self, file_path: str, content: str) -> WriteResult:
if any(file_path.startswith(p) for p in self.deny_prefixes):
return WriteResult(error=f"Writes are not allowed under {file_path}")
return super().write(file_path, content)
def edit(self, file_path: str, old_string: str, new_string: str, replace_all: bool = False) -> EditResult:
if any(file_path.startswith(p) for p in self.deny_prefixes):
return EditResult(error=f"Edits are not allowed under {file_path}")
return super().edit(file_path, old_string, new_string, replace_all)高级示例 - 通用策略包装
from deepagents.backends.protocol import BackendProtocol, WriteResult, EditResult
from deepagents.backends.utils import FileInfo, GrepMatch
class PolicyWrapper(BackendProtocol):
def __init__(self, inner: BackendProtocol, deny_prefixes: list[str] | None = None):
self.inner = inner
self.deny_prefixes = [p if p.endswith("/") else p + "/" for p in (deny_prefixes or [])]
def _deny(self, path: str) -> bool:
return any(path.startswith(p) for p in self.deny_prefixes)
def ls_info(self, path: str) -> list[FileInfo]:
return self.inner.ls_info(path)
def read(self, file_path: str, offset: int = 0, limit: int = 2000) -> str:
return self.inner.read(file_path, offset=offset, limit=limit)
def grep_raw(self, pattern: str, path: str | None = None, glob: str | None = None) -> list[GrepMatch] | str:
return self.inner.grep_raw(pattern, path, glob)
def glob_info(self, pattern: str, path: str = "/") -> list[FileInfo]:
return self.inner.glob_info(pattern, path)
def write(self, file_path: str, content: str) -> WriteResult:
if self._deny(file_path):
return WriteResult(error=f"Writes are not allowed under {file_path}")
return self.inner.write(file_path, content)
def edit(self, file_path: str, old_string: str, new_string: str, replace_all: bool = False) -> EditResult:
if self._deny(file_path):
return EditResult(error=f"Edits are not allowed under {file_path}")
return self.inner.edit(file_path, old_string, new_string, replace_all)BackendProtocol 接口说明
| 方法 | 签名 | 说明 |
|---|---|---|
ls_info | (path: str) -> list[FileInfo] | 列出指定 path 下的文件和目录 |
read | (file_path: str, offset: int = 0, limit: int = 2000) -> str | 读取文件内容,支持分页 |
grep_raw | (pattern: str, path: Optional[str] = None, glob: Optional[str] = None) -> list[GrepMatch] | str | 搜索文件内容匹配 |
glob_info | (pattern: str, path: str = "/") -> list[FileInfo] | 按模式匹配返回 FileInfo |
write | (file_path: str, content: str) -> WriteResult | 创建新文件 |
edit | (file_path: str, old_string: str, new_string: str, replace_all: bool = False) -> EditResult | 替换文件内容,支持 replace_all=True |
子智能体(Subagents)
子智能体允许 Deep Agent 将复杂任务委托给专门化的智能体。每个子智能体可以有自己独立的工具、提示和模型,在隔离的上下文中运行,完成后将结果返回给主智能体。
子智能体架构
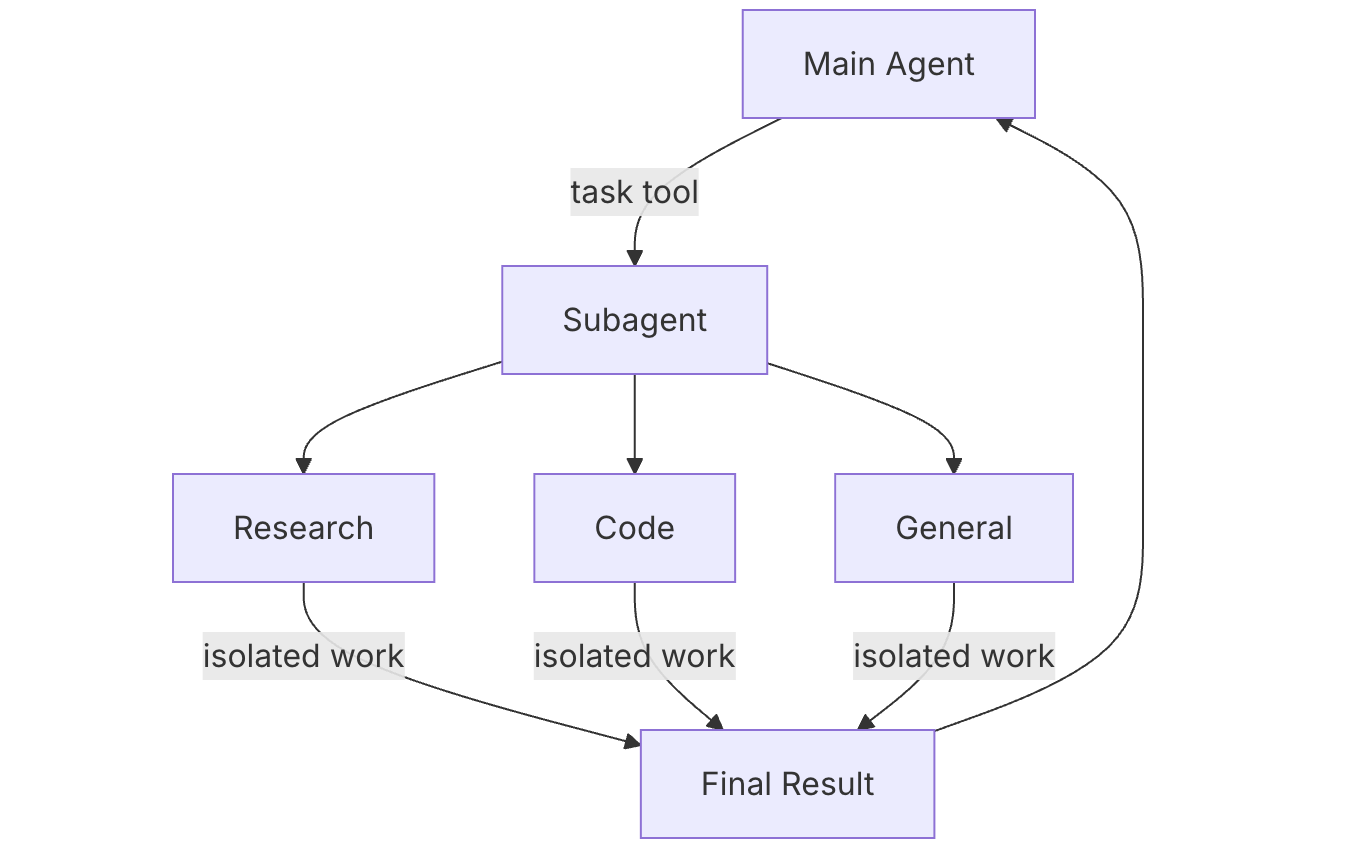
graph TD
A[Main Agent] --> B[Delegation]
B --> C[Research Subagent]
B --> D[Code Subagent]
B --> E[General Subagent]
C --> C1[Isolated Work]
D --> D1[Isolated Work]
E --> E1[Isolated Work]
C1 --> F[Final Result]
D1 --> F
E1 --> F
F --> A何时使用子智能体
适合使用:
- 需要处理多个独立的专业领域
- 希望隔离不同任务的上下文
- 需要使用不同模型处理不同任务
- 主智能体任务过于复杂
不适合:
- 简单的单一任务
- 需要频繁的上下文共享
- 所有任务使用相同工具
配置选项
SubAgent(字典)
必需字段:
name: 唯一的会话级名称description: 帮助主智能体理解何时应该使用system_prompt: 专门的行为和风格配置tools: 子智能体专属的工具列表
可选字段:
model: 为子智能体指定不同模型(格式"provider:model-name")middleware: 配置中间件,如待办事项管理interrupt_on: Human-in-the-loop 配置(需要 checkpointer)
CompiledSubAgent(编译后)
直接传入已有的 LangGraph 编译图:
name: 唯一名称description: 功能描述runnable: 已编译的 LangGraph 图(使用.compile())
创建子智能体示例
import os
from typing import Literal
from tavily import TavilyClient
from deepagents import create_deep_agent
tavily_client = TavilyClient(api_key=os.environ["TAVILY_API_KEY"])
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
):
"""Run a web search"""
return tavily_client.search(
query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)
# 定义研究子智能体
research_subagent = {
"name": "research-agent",
"description": "Used to research more in depth questions",
"system_prompt": "You are a great researcher",
"tools": [internet_search],
"model": "openai:gpt-4o",
}
subagents = [research_subagent]
# 将子智能体添加到 Deep Agent
agent = create_deep_agent(
model="claude-sonnet-4-5-20250929",
subagents=subagents
)CompiledSubAgent 示例
from deepagents import create_deep_agent, CompiledSubAgent
from langchain.agents import create_agent
# 创建自定义图
custom_graph = create_agent(
model=your_model,
tools=specialized_tools,
prompt="You are a specialized agent for data analysis..."
)
# 包装为 CompiledSubAgent
custom_subagent = CompiledSubAgent(
name="data-analyzer",
description="Specialized agent for complex data analysis tasks",
runnable=custom_graph
)
subagents = [custom_subagent]
agent = create_deep_agent(
model="claude-sonnet-4-5-20250929",
tools=[internet_search],
system_prompt=research_instructions,
subagents=subagents
)使用子智能体
主智能体通过 Deep Agent 内置的 task 工具调用子智能体:
- 主智能体描述需要完成的任务
- 选择合适的子智能体执行
- 接收并整合结果
子智能体会在独立的上下文中运行。
最佳实践
清晰的描述
✓ "Analyzes financial data and generates investment insights with confidence scores"
✗ "Does finance stuff"专注的功能范围: 让子智能体专注于特定领域,而不是成为通用助手。
合理的工具配置: 只提供子智能体真正需要的工具,避免过载。
独立的模型选择: 根据任务复杂度为子智能体选择合适的模型。
隔离的上下文: 为子智能体设置清晰的会话边界。
常见问题
| 问题 | 解决方案 |
|---|---|
| 子智能体未被调用 | 检查工具描述是否清晰,主智能体是否理解何时使用 |
| 上下文泄露 | 确认子智能体配置了独立的上下文和工具 |
| 性能问题 | 考虑为简单任务使用轻量级模型 |
Human-in-the-Loop(人机协作)
使用 LangGraph 的中断功能,可以在关键工具调用前暂停执行,等待人工审批。
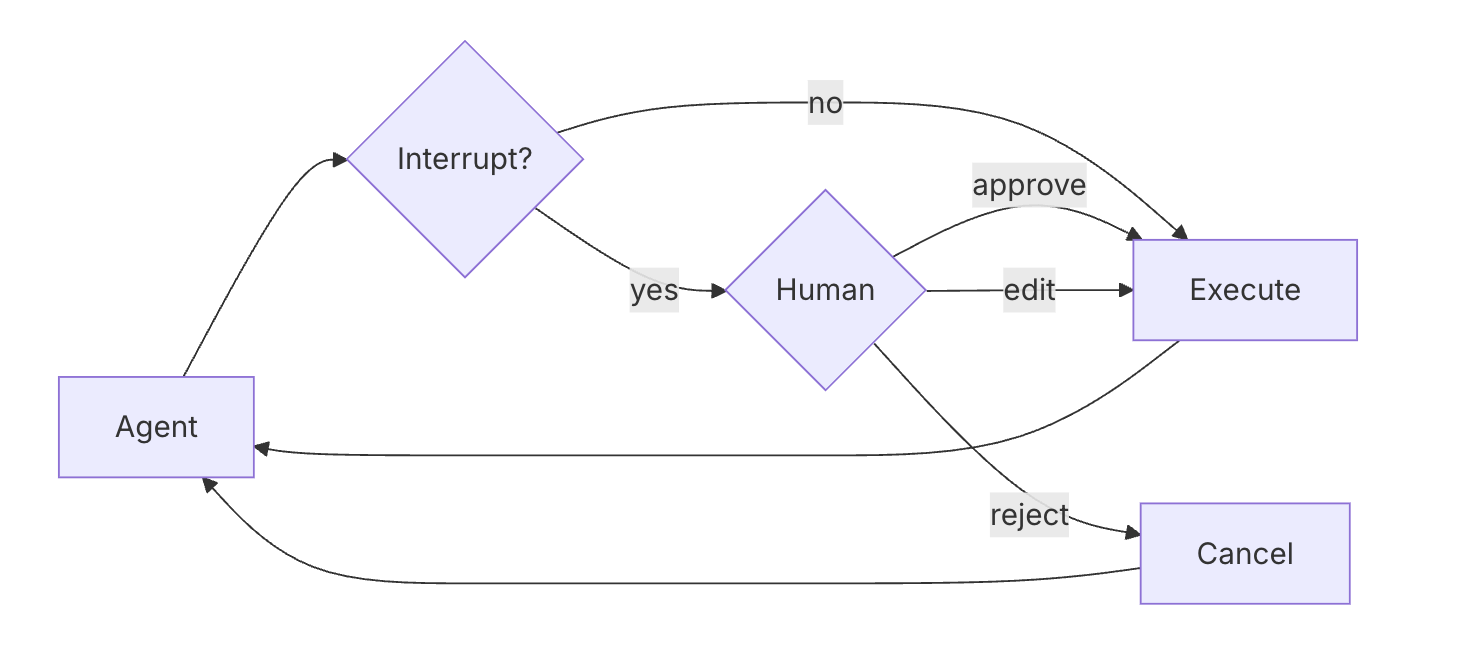
基本配置
interrupt_on 参数控制工具调用的中断行为:
True: 所有工具调用都会触发中断(默认情况下仅在危险操作时)False: 禁用中断{"allowed_decisions": [...]}: 自定义配置允许的决策类型
⚠️ 重要提示: Human-in-the-loop 功能必须配合 checkpointer 使用,否则无法保存状态。
决策选项
所有待审批的工具调用都可以执行以下操作:
| 决策 | 说明 |
|---|---|
| Approve | 允许智能体按原计划执行 |
| Edit | 在执行前修改工具参数 |
| Reject | 阻止该工具执行 |
实现流程
基本流程:
- 检查
result.get("__interrupt__")判断是否需要审批 - 获取中断信息中的
action_requests和review_configs - 分析每个请求并做出决策
- 使用
Command(resume={"decisions": decisions})继续
多工具处理
当多个工具需要审批时,需要为每个工具提供决策。action_requests 中会包含智能体请求的所有工具调用。
编辑参数
当选择 "edit" 决策时,需要提供修改后的参数:
{
"decision": "edit",
"edited_action": {
"name": action_request["name"],
"args": {
# 修改后的参数
}
}
}子智能体中断
子智能体也可以独立配置中断行为,继承主智能体的 interrupt_on 配置。
最佳实践
- 必须使用 checkpointer(如
MemorySaver()) - 在 invoke 和 resume 间保持相同的
thread_id - 处理所有
action_requests中的决策 - 配置合理的中断策略:高风险工具中断,低风险工具跳过
长期记忆
使用 CompositeBackend 实现跨会话的持久化存储。
架构图
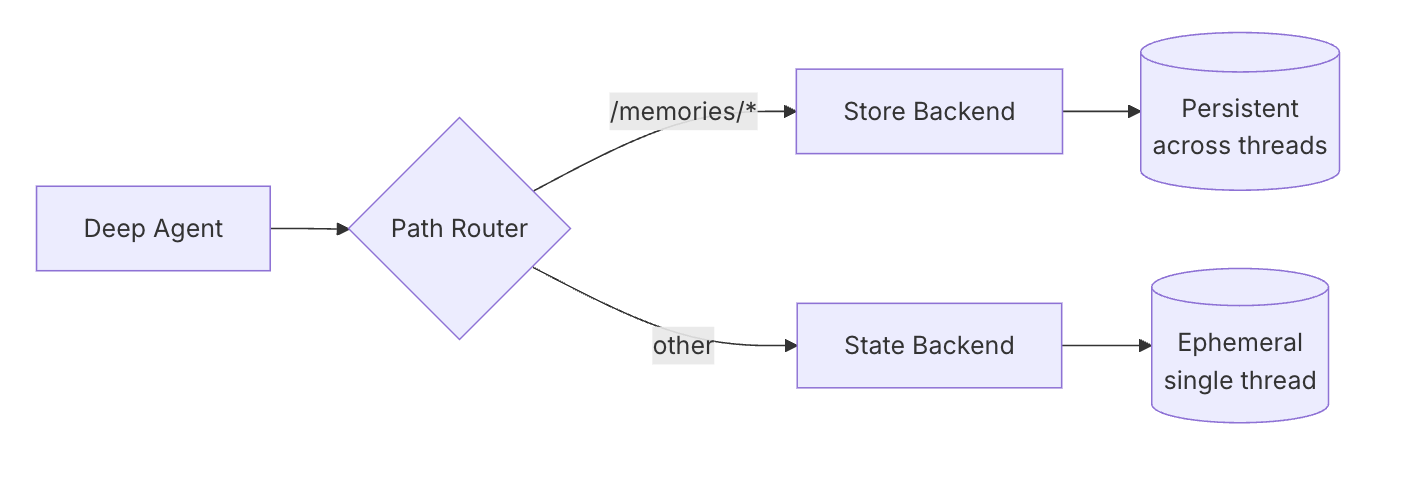
graph LR
A[Deep Agent] --> B[Path Router]
B -->|/memories/*| C[Store Backend]
B -->|其他路径| D[State Backend]
C --> E[持久存储]
D --> F[临时会话]基础配置
from deepagents import create_deep_agent
from deepagents.backends import CompositeBackend, StateBackend, StoreBackend
from langgraph.store.memory import InMemoryStore
def make_backend(runtime):
return CompositeBackend(
default=StateBackend(runtime), # 临时会话
routes={
"/memories/": StoreBackend(runtime) # 持久存储
}
)
agent = create_deep_agent(
store=InMemoryStore(), # StoreBackend 需要
backend=make_backend
)功能说明
临时数据:
- 使用
StateBackend存储在智能体内存中 - 会话结束后丢失
- 适合草稿等临时内容
- 示例:
/notes.txt,/workspace/draft.md
持久数据:
- 使用
StoreBackend存储到 LangGraph Store 中 - 跨会话保留
- 使用
/memories/前缀,如:/memories/preferences.txt
路由规则对比
| 路径 | 存储位置 |
|---|---|
/memories/* | 持久存储 |
| 其他 | 临时存储 |
智能体通过文件路径来决定数据存储方式。
示例
# 临时文件:会话结束后丢失
agent.invoke({
"messages": [{"role": "user", "content": "Write draft to /draft.txt"}]
})
# 持久文件:跨会话保留
agent.invoke({
"messages": [{"role": "user", "content": "Save final report to /memories/report.txt"}]
})跨会话访问
import uuid
# 会话 1:保存偏好
config1 = {"configurable": {"thread_id": str(uuid.uuid4())}}
agent.invoke({
"messages": [{"role": "user", "content": "Save my preferences to /memories/preferences.txt"}]
}, config=config1)
# 会话 2:读取之前保存的偏好
config2 = {"configurable": {"thread_id": str(uuid.uuid4())}}
agent.invoke({
"messages": [{"role": "user", "content": "What are my preferences?"}]
}, config=config2)使用场景
保存用户偏好
agent = create_deep_agent(
store=InMemoryStore(),
backend=lambda rt: CompositeBackend(
default=StateBackend(rt),
routes={"/memories/": StoreBackend(rt)}
),
system_prompt="""When users tell you their preferences, save them to
/memories/user_preferences.txt so you remember them in future conversations."""
)自我修改指令
agent = create_deep_agent(
store=InMemoryStore(),
backend=lambda rt: CompositeBackend(
default=StateBackend(rt),
routes={"/memories/": StoreBackend(rt)}
),
system_prompt="""You have a file at /memories/instructions.txt with additional
instructions and preferences.
Read this file at the start of conversations to understand user preferences.
When users provide feedback like "please always do X" or "I prefer Y",
update /memories/instructions.txt using the edit_file tool."""
)研究项目
research_agent = create_deep_agent(
store=InMemoryStore(),
backend=lambda rt: CompositeBackend(
default=StateBackend(rt),
routes={"/memories/": StoreBackend(rt)}
),
system_prompt="""You are a research assistant.
Save your research progress to /memories/research/:
- /memories/research/sources.txt - List of sources found
- /memories/research/notes.txt - Key findings and notes
- /memories/research/report.md - Final report draft
This allows research to continue across multiple sessions."""
)Store 选项
InMemoryStore(仅内存)
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
agent = create_deep_agent(
store=store,
backend=lambda rt: CompositeBackend(
default=StateBackend(rt),
routes={"/memories/": StoreBackend(rt)}
)
)PostgresStore(生产环境)
from langgraph.store.postgres import PostgresStore
import os
store = PostgresStore(connection_string=os.environ["DATABASE_URL"])
agent = create_deep_agent(
store=store,
backend=lambda rt: CompositeBackend(
default=StateBackend(rt),
routes={"/memories/": StoreBackend(rt)}
)
)最佳实践
使用有意义的路径
/memories/user_preferences.txt/memories/research/topic_a/sources.txt/memories/project/requirements.md
在系统提示中指导智能体何时保存文件,避免过度存储配置。
测试跨会话行为,确保记忆正确持久化。
选择合适的存储
- 开发:
InMemoryStore - 生产:
PostgresStore或其他持久存储 - 多租户:考虑使用
assistant_id来隔离
- 开发:
中间件(Middleware)
Deep Agent 支持三种内置中间件,它们提供了常用功能的工具、后端存储和子智能体支持。
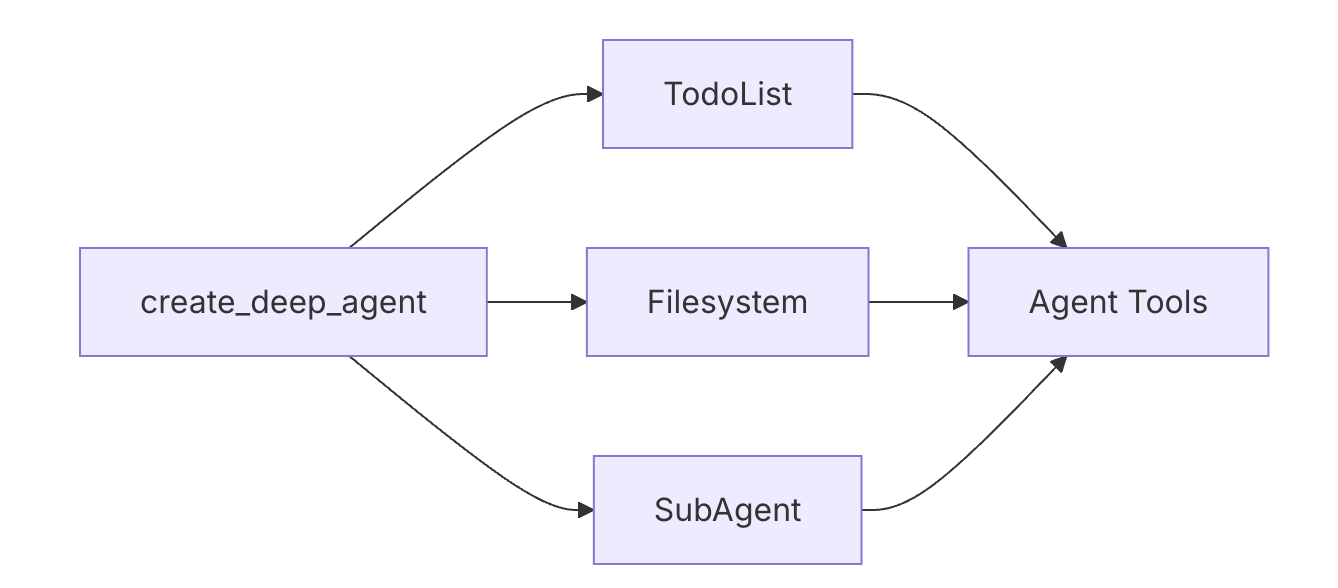
三种内置中间件
1. TodoListMiddleware
启用智能体的任务管理能力,给智能体添加 write_todos 工具来创建和管理待办事项。
from langchain.agents import create_agent
from langchain.agents.middleware import TodoListMiddleware
agent = create_agent(
model="claude-sonnet-4-5-20250929",
middleware=[
TodoListMiddleware(
system_prompt="Use the write_todos tool to..."
),
],
)2. FilesystemMiddleware
提供文件系统操作的一套工具:ls、read_file、write_file 和 edit_file。
默认存储: 会话临时。持久存储: 配置 CompositeBackend 将 /memories/ 路由到 StoreBackend。
from deepagents.middleware import FilesystemMiddleware
from deepagents.backends import CompositeBackend, StateBackend, StoreBackend
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
agent = create_agent(
model="claude-sonnet-4-5-20250929",
store=store,
middleware=[
FilesystemMiddleware(
backend=lambda rt: CompositeBackend(
default=StateBackend(rt),
routes={"/memories/": StoreBackend(rt)}
),
),
],
)3. SubAgentMiddleware
子智能体支持。允许主智能体创建子智能体来执行任务,每个子智能体有独立的工具、提示、模型和中间件。
from langchain.tools import tool
from langchain.agents import create_agent
from deepagents.middleware.subagents import SubAgentMiddleware
@tool
def get_weather(city: str) -> str:
"""Get the weather in a city."""
return f"The weather in {city} is sunny."
agent = create_agent(
model="claude-sonnet-4-5-20250929",
middleware=[
SubAgentMiddleware(
default_model="claude-sonnet-4-5-20250929",
default_tools=[],
subagents=[
{
"name": "weather",
"description": "This subagent can get weather in cities.",
"system_prompt": "Use the get_weather tool...",
"tools": [get_weather],
"model": "gpt-4o",
"middleware": [],
}
],
)
],
)编译后的图也可以通过 CompiledSubAgent 传入,让你集成任意自定义智能体。
CLI 命令行工具
命令行工具方便快速测试和使用智能体。
核心功能
| 功能 | 说明 |
|---|---|
| 交互式对话 | 与智能体直接交互,支持多轮对话 |
| Shell 命令执行 | 智能体可以执行系统命令(如需要 Tavily API key) |
| 网络搜索 | 配置 API key 后可搜索网络 |
| HTTP 请求 | 发送 API 请求,支持 HTTP 协议 |
| 任务和文件管理 | 管理任务列表和文件读写操作 |
| 跨会话记忆 | 支持跨会话记忆存储 |
| Human-in-the-loop | 关键工具调用前等待确认 |
快速开始
步骤 1:设置 API Key
# 方式 A - 环境变量
export ANTHROPIC_API_KEY="your-api-key"
# 方式 B - .env 文件
ANTHROPIC_API_KEY=your-api-key步骤 2:启动 CLI
uvx deepagents-cli步骤 3:开始交互
> Create a Python script that prints "Hello, World!"智能体会在当前目录创建文件,修改文件,并等待你确认。
安装方式
使用 pip:
pip install deepagents-cli使用 uv:
uv add deepagents-cli模型配置
默认: Anthropic Claude Sonnet 4
使用 OpenAI:
export OPENAI_API_KEY="your-key"网络搜索(可选):
export TAVILY_API_KEY="your-key"命令行选项
| 选项 | 说明 |
|---|---|
--agent NAME | 使用特定名称的智能体 |
--auto-approve | 跳过工具确认(或使用 Ctrl+T 切换) |
--sandbox TYPE | 使用云沙箱运行:modal、daytona 或 runloop |
--sandbox-id ID | 复用现有沙箱 |
--sandbox-setup PATH | 指定沙箱设置脚本 |
CLI 命令
| 命令 | 说明 |
|---|---|
deepagents list | 列出所有智能体 |
deepagents help | 显示帮助 |
deepagents reset --agent NAME | 将智能体重置为默认 |
deepagents reset --agent NAME --target SOURCE | 复制其他智能体的配置 |
交互命令
斜杠命令
| 命令 | 说明 |
|---|---|
/tokens | 显示当前使用的 token 数 |
/clear | 清除上下文 |
/exit | 退出 CLI |
Bash 命令
以 ! 前缀运行 shell 命令:
!git status
!npm test
!ls -la快捷键
| 快捷键 | 功能 |
|---|---|
Enter | 发送 |
Alt+Enter | 换行 |
Ctrl+E | 打开编辑器 |
Ctrl+T | 切换自动确认 |
Ctrl+C | 中断 |
Ctrl+D | 退出 |
持久化记忆
每个智能体关键配置会自动持久化:
- 规划 - 存储在指定路径下的工作目录
- 偏好 - 用户执行习惯和配置
- 文件 - 跨会话的文件读写操作
文件组织
~/.deepagents/backend-dev/memories/
api-conventions.md
database-schema.md
deployment-process.md使用示例
存储偏好
uvx deepagents-cli --agent backend-dev
> Our API uses snake_case and includes created_at/updated_at timestamps后续使用自动应用
> Create a /users endpoint
# 自动应用之前存储的规范云沙箱
优势
| 优势 | 说明 |
|---|---|
| 隔离 | 在独立环境中运行,不影响本地 |
| 预配置环境 | 可以预先安装依赖和配置 |
| 并行执行 | 可在云端同时运行多个智能体 |
| 持久化环境 | 运行结束后环境保留 |
| 可审计 | 便于审查智能体的所有操作 |
配置步骤
步骤 1 - 配置云服务提供商
# Runloop:
export RUNLOOP_API_KEY="your-key"
# Daytona:
export DAYTONA_API_KEY="your-key"
# Modal:
modal setup步骤 2 - 使用沙箱启动 CLI
uvx deepagents-cli --sandbox runloop --sandbox-setup ./setup.sh步骤 3(可选)- 配置 setup.sh
#!/bin/bash
set -e
# 使用 GitHub token 克隆仓库
git clone https://x-access-token:${GITHUB_TOKEN}@github.com/username/repo.git $HOME/workspace
cd $HOME/workspace
# 设置环境变量
cat >> ~/.bashrc <<'EOF'
export GITHUB_TOKEN="${GITHUB_TOKEN}"
export OPENAI_API_KEY="${OPENAI_API_KEY}"
cd $HOME/workspace
EOF
source ~/.bashrc⚠️ 安全警告: 云沙箱中运行的智能体可以访问配置的所有凭据。建议为智能体创建专用账户并配合 human-in-the-loop 确认敏感操作。
参考资源
完整案例代码(可直接运行)
以下是一个完整的 Deep Agents 示例,展示了核心功能的使用方式:
"""
Deep Agents 完整示例
演示:工具定义、后端配置、子智能体、长期记忆
场景:智能研究助手
1. 主智能体接收用户问题
2. 使用网络搜索工具获取信息
3. 可选择委托给专门的子智能体
4. 支持跨会话的长期记忆
"""
import os
from typing import Literal, List
from typing_extensions import TypedDict
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
# ========== 1. 数据模型定义 ==========
class SearchResult(BaseModel):
"""搜索结果模型"""
title: str = Field(description="结果标题")
snippet: str = Field(description="内容摘要")
source: str = Field(description="来源")
class ResearchReport(BaseModel):
"""研究报告模型"""
topic: str = Field(description="研究主题")
summary: str = Field(description="摘要")
key_findings: List[str] = Field(description="关键发现")
sources: List[str] = Field(description="参考来源")
# ========== 2. 工具定义 ==========
@tool
def search_web(query: str, max_results: int = 3) -> str:
"""
搜索网络信息。
Args:
query: 搜索查询字符串
max_results: 返回结果数量,默认3条
"""
# 模拟搜索结果(实际应用中使用 Tavily API)
results = [
{
"title": f"关于 {query} 的权威介绍",
"snippet": f"这是关于 {query} 的详细解释。Deep Agents 是一个强大的智能体框架...",
"source": "docs.example.com"
},
{
"title": f"{query} 最佳实践指南",
"snippet": f"学习 {query} 的最佳方法包括:理解核心概念、动手实践、阅读源码...",
"source": "guide.example.com"
},
{
"title": f"{query} 实战案例分析",
"snippet": f"在实际项目中应用 {query},可以显著提高开发效率和代码质量...",
"source": "blog.example.com"
}
]
formatted = "\n\n".join([
f"📌 {r['title']}\n {r['snippet']}\n 来源: {r['source']}"
for r in results[:max_results]
])
print(f"🔍 搜索完成: {query}")
return formatted
@tool
def read_document(path: str) -> str:
"""
读取本地文档内容。
Args:
path: 文档路径
"""
# 模拟文档读取
print(f"📄 读取文档: {path}")
return f"文档 {path} 的内容:这是一份关于 AI 技术的详细文档..."
@tool
def write_notes(content: str, filename: str = "notes.txt") -> str:
"""
保存笔记到文件。
Args:
content: 笔记内容
filename: 文件名,默认 notes.txt
"""
print(f"📝 保存笔记到: {filename}")
return f"笔记已保存到 {filename}"
@tool
def calculate(expression: str) -> str:
"""
计算数学表达式。
Args:
expression: 数学表达式,如 '2 + 2 * 3'
"""
try:
result = eval(expression)
print(f"🔢 计算: {expression} = {result}")
return f"计算结果: {result}"
except Exception as e:
return f"计算错误: {str(e)}"
# ========== 3. 模拟 Deep Agent 核心功能 ==========
class SimpleDeepAgent:
"""
简化版 Deep Agent 实现
展示核心概念:工具调用、任务管理、记忆系统
"""
def __init__(
self,
model: str = "gpt-4o-mini",
tools: List = None,
system_prompt: str = None,
name: str = "deep-agent"
):
self.name = name
self.llm = ChatOpenAI(model=model, temperature=0.7)
self.tools = tools or []
self.system_prompt = system_prompt or "你是一个智能助手。"
self.memory = [] # 简单的内存存储
self.todos = [] # 任务列表
# 绑定工具到 LLM
if self.tools:
self.llm_with_tools = self.llm.bind_tools(self.tools)
else:
self.llm_with_tools = self.llm
print(f"🤖 Agent [{self.name}] 初始化完成")
print(f" 工具: {[t.name for t in self.tools]}")
def add_todo(self, task: str, status: str = "pending"):
"""添加任务到待办列表"""
self.todos.append({"task": task, "status": status})
print(f"📋 添加任务: {task}")
def update_todo(self, task_index: int, status: str):
"""更新任务状态"""
if 0 <= task_index < len(self.todos):
self.todos[task_index]["status"] = status
print(f"✅ 任务状态更新: {self.todos[task_index]['task']} -> {status}")
def save_to_memory(self, key: str, value: str):
"""保存到长期记忆"""
self.memory.append({"key": key, "value": value})
print(f"💾 保存到记忆: {key}")
def get_from_memory(self, key: str) -> str:
"""从记忆中获取"""
for item in self.memory:
if item["key"] == key:
return item["value"]
return None
def invoke(self, messages: List[dict]) -> dict:
"""
执行智能体推理
Args:
messages: 消息列表,格式 [{"role": "user", "content": "..."}]
Returns:
包含响应消息的字典
"""
# 构建消息
formatted_messages = [SystemMessage(content=self.system_prompt)]
for msg in messages:
if msg["role"] == "user":
formatted_messages.append(HumanMessage(content=msg["content"]))
elif msg["role"] == "assistant":
formatted_messages.append(AIMessage(content=msg["content"]))
# 调用 LLM
response = self.llm_with_tools.invoke(formatted_messages)
# 检查是否有工具调用
if hasattr(response, 'tool_calls') and response.tool_calls:
tool_results = []
for tool_call in response.tool_calls:
tool_name = tool_call["name"]
tool_args = tool_call["args"]
# 查找并执行工具
for tool in self.tools:
if tool.name == tool_name:
result = tool.invoke(tool_args)
tool_results.append({
"tool": tool_name,
"result": result
})
break
# 将工具结果反馈给 LLM 生成最终回答
tool_context = "\n".join([
f"工具 {r['tool']} 返回:\n{r['result']}"
for r in tool_results
])
final_prompt = f"""基于以下工具调用结果,回答用户问题:
{tool_context}
请给出简洁、有帮助的回答。"""
formatted_messages.append(AIMessage(content=response.content or ""))
formatted_messages.append(HumanMessage(content=final_prompt))
final_response = self.llm.invoke(formatted_messages)
return {"messages": [{"role": "assistant", "content": final_response.content}]}
return {"messages": [{"role": "assistant", "content": response.content}]}
def stream(self, messages: List[dict]):
"""流式执行(简化版)"""
print("⏳ 处理中...")
# Step 1: 分析任务
yield {"step": "analyze", "content": "正在分析用户请求..."}
# Step 2: 执行
result = self.invoke(messages)
yield {"step": "complete", "content": result["messages"][0]["content"]}
# ========== 4. 子智能体定义 ==========
class ResearchSubAgent(SimpleDeepAgent):
"""研究专用子智能体"""
def __init__(self):
super().__init__(
name="research-agent",
tools=[search_web, read_document],
system_prompt="""你是一个专业的研究助手。
你的职责是:
1. 搜索和整理相关信息
2. 分析和总结关键发现
3. 提供有据可查的回答
始终引用信息来源。"""
)
class CalculationSubAgent(SimpleDeepAgent):
"""计算专用子智能体"""
def __init__(self):
super().__init__(
name="calc-agent",
tools=[calculate],
system_prompt="""你是一个计算助手。
准确执行数学计算,并解释计算过程。"""
)
# ========== 5. 主智能体(协调器) ==========
class OrchestratorAgent(SimpleDeepAgent):
"""
协调器智能体
管理子智能体并分配任务
"""
def __init__(self):
super().__init__(
name="orchestrator",
tools=[search_web, calculate, write_notes],
system_prompt="""你是一个智能协调助手。
你可以:
1. 使用 search_web 搜索网络信息
2. 使用 calculate 进行数学计算
3. 使用 write_notes 保存笔记
根据用户需求选择合适的工具。"""
)
# 注册子智能体
self.subagents = {
"research": ResearchSubAgent(),
"calculation": CalculationSubAgent()
}
def delegate_to_subagent(self, agent_name: str, task: str) -> str:
"""委托任务给子智能体"""
if agent_name in self.subagents:
print(f"📤 委托任务给 [{agent_name}]: {task[:50]}...")
subagent = self.subagents[agent_name]
result = subagent.invoke([{"role": "user", "content": task}])
return result["messages"][0]["content"]
return f"未找到子智能体: {agent_name}"
# ========== 6. 后端存储模拟 ==========
class SimpleBackend:
"""
简化版后端存储
模拟 StateBackend + StoreBackend 组合
"""
def __init__(self):
self.state = {} # 临时状态(会话内)
self.store = {} # 持久存储(跨会话)
def write_state(self, key: str, value: any):
"""写入临时状态"""
self.state[key] = value
print(f"💾 [State] 写入: {key}")
def read_state(self, key: str) -> any:
"""读取临时状态"""
return self.state.get(key)
def write_store(self, path: str, content: str):
"""写入持久存储"""
self.store[path] = content
print(f"💾 [Store] 持久化: {path}")
def read_store(self, path: str) -> str:
"""读取持久存储"""
return self.store.get(path, "")
def list_store(self) -> List[str]:
"""列出所有持久化文件"""
return list(self.store.keys())
# ========== 7. 完整的 Deep Agent 系统 ==========
class DeepAgentSystem:
"""
完整的 Deep Agent 系统
整合:智能体、后端、记忆、任务管理
"""
def __init__(self):
self.backend = SimpleBackend()
self.agent = OrchestratorAgent()
self.conversation_history = []
def chat(self, user_input: str) -> str:
"""处理用户输入"""
print(f"\n{'='*50}")
print(f"👤 用户: {user_input}")
print('='*50)
# 添加到对话历史
self.conversation_history.append({
"role": "user",
"content": user_input
})
# 添加任务
self.agent.add_todo(f"处理: {user_input[:30]}...", "in_progress")
# 执行智能体
result = self.agent.invoke(self.conversation_history)
response = result["messages"][0]["content"]
# 更新对话历史
self.conversation_history.append({
"role": "assistant",
"content": response
})
# 更新任务状态
self.agent.update_todo(len(self.agent.todos) - 1, "completed")
# 保存到记忆(模拟长期记忆)
self.backend.write_store(
f"/memories/conversation_{len(self.conversation_history)}.txt",
f"Q: {user_input}\nA: {response[:200]}..."
)
print(f"\n🤖 助手: {response}")
return response
def show_status(self):
"""显示系统状态"""
print(f"\n{'='*50}")
print("📊 系统状态")
print('='*50)
print(f"\n📋 任务列表 ({len(self.agent.todos)} 项):")
for i, todo in enumerate(self.agent.todos):
status_icon = "✅" if todo["status"] == "completed" else "⏳"
print(f" {status_icon} {todo['task']}")
print(f"\n💾 持久化存储 ({len(self.backend.store)} 项):")
for path in self.backend.list_store():
print(f" 📄 {path}")
print(f"\n💬 对话历史 ({len(self.conversation_history)} 条消息)")
# ========== 8. 主程序 ==========
if __name__ == "__main__":
print("=" * 60)
print("🚀 Deep Agents 完整示例")
print("=" * 60)
# 创建系统
system = DeepAgentSystem()
# 测试对话
print("\n" + "=" * 60)
print("💬 开始对话测试")
print("=" * 60)
# 问题 1: 搜索任务
system.chat("什么是 LangGraph?请搜索相关信息")
# 问题 2: 计算任务
system.chat("计算 15 * 8 + 42 的结果")
# 问题 3: 综合任务
system.chat("总结一下 AI Agent 的主要特点")
# 显示系统状态
system.show_status()
# 演示子智能体委托
print("\n" + "=" * 60)
print("📤 子智能体委托演示")
print("=" * 60)
orchestrator = system.agent
research_result = orchestrator.delegate_to_subagent(
"research",
"研究 Deep Agents 框架的核心特性"
)
print(f"\n研究结果: {research_result[:200]}...")
# 演示后端存储
print("\n" + "=" * 60)
print("💾 后端存储演示")
print("=" * 60)
backend = system.backend
# 写入临时状态
backend.write_state("current_task", "研究 Deep Agents")
backend.write_state("user_preferences", {"theme": "dark", "language": "zh"})
# 写入持久存储
backend.write_store("/memories/user_profile.txt", "用户偏好: 中文,技术话题")
backend.write_store("/memories/research_notes.md", "# Deep Agents 研究笔记\n\n- 支持子智能体\n- 内置任务管理")
# 读取验证
print(f"\n读取临时状态: {backend.read_state('current_task')}")
print(f"读取持久存储: {backend.read_store('/memories/user_profile.txt')}")
# 最终状态
print("\n" + "=" * 60)
print("✅ 演示完成")
print("=" * 60)
print(f"""
📋 核心知识点回顾:
| 概念 | 说明 | 代码示例 |
|------|------|----------|
| **@tool 装饰器** | 定义智能体工具 | `@tool def search(query: str)` |
| **工具绑定** | 将工具绑定到 LLM | `llm.bind_tools([tool1, tool2])` |
| **子智能体** | 专门化任务处理 | `delegate_to_subagent("research", task)` |
| **任务管理** | 待办事项追踪 | `add_todo()`, `update_todo()` |
| **后端存储** | 状态/持久化分离 | `StateBackend`, `StoreBackend` |
| **长期记忆** | 跨会话数据存储 | `/memories/` 路径路由 |
| **消息历史** | 对话上下文管理 | `conversation_history` |
""")运行结果示例
============================================================
🚀 Deep Agents 完整示例
============================================================
🤖 Agent [orchestrator] 初始化完成
工具: ['search_web', 'calculate', 'write_notes']
🤖 Agent [research-agent] 初始化完成
工具: ['search_web', 'read_document']
🤖 Agent [calc-agent] 初始化完成
工具: ['calculate']
============================================================
💬 开始对话测试
============================================================
==================================================
👤 用户: 什么是 LangGraph?请搜索相关信息
==================================================
📋 添加任务: 处理: 什么是 LangGraph?请搜索相关信息...
🔍 搜索完成: LangGraph
✅ 任务状态更新: 处理: 什么是 LangGraph?请搜索相关信息... -> completed
💾 [Store] 持久化: /memories/conversation_2.txt
🤖 助手: LangGraph 是一个强大的 AI 应用框架,具有以下特点...
==================================================
👤 用户: 计算 15 * 8 + 42 的结果
==================================================
📋 添加任务: 处理: 计算 15 * 8 + 42 的结果...
🔢 计算: 15 * 8 + 42 = 162
✅ 任务状态更新: 处理: 计算 15 * 8 + 42 的结果... -> completed
🤖 助手: 计算结果是 162。计算过程:15 × 8 = 120,然后 120 + 42 = 162。
==================================================
📊 系统状态
==================================================
📋 任务列表 (3 项):
✅ 处理: 什么是 LangGraph?请搜索相关信息...
✅ 处理: 计算 15 * 8 + 42 的结果...
✅ 处理: 总结一下 AI Agent 的主要特点...
💾 持久化存储 (4 项):
📄 /memories/conversation_2.txt
📄 /memories/conversation_4.txt
📄 /memories/conversation_6.txt
💬 对话历史 (6 条消息)
============================================================
📤 子智能体委托演示
============================================================
📤 委托任务给 [research]: 研究 Deep Agents 框架的核心特性...
🔍 搜索完成: Deep Agents 框架核心特性
研究结果: Deep Agents 是一个基于 LangGraph 构建的高级智能体框架...
============================================================
💾 后端存储演示
============================================================
💾 [State] 写入: current_task
💾 [State] 写入: user_preferences
💾 [Store] 持久化: /memories/user_profile.txt
💾 [Store] 持久化: /memories/research_notes.md
读取临时状态: 研究 Deep Agents
读取持久存储: 用户偏好: 中文,技术话题
============================================================
✅ 演示完成
============================================================核心知识点回顾
| 概念 | 说明 | 代码示例 |
|---|---|---|
| @tool 装饰器 | 将函数转为 LangChain 工具 | @tool def search(query: str) |
| 工具绑定 | 让 LLM 能调用工具 | llm.bind_tools([tool1, tool2]) |
| 子智能体 | 专门化的任务处理单元 | ResearchSubAgent() |
| 任务委托 | 主智能体分配任务 | delegate_to_subagent("research", task) |
| 任务管理 | 待办事项追踪 | add_todo(), update_todo() |
| 后端存储 | 状态与持久化分离 | StateBackend + StoreBackend |
| 长期记忆 | 跨会话数据存储 | /memories/ 路径路由 |
| CompositeBackend | 组合多个后端 | 路由不同路径到不同存储 |
总结: Deep Agents 提供了构建生产级 AI 智能体的完整解决方案,包括子智能体、人机协作、长期记忆等高级功能。无论是通过 Python API 还是 CLI,Deep Agents 都能帮助你快速构建可靠的智能体系统。